
 All guides
All guidesHow to accelerate labeling projects using GPT–4V in Foundry
Working closely with hundreds of companies at the forefront of AI, we are seeing a growing interest from teams wanting to use foundation models to pre-label data before combining a human-in-the-loop workflow to inject their unique domain expertise and automate specific tasks that have been previously very time-consuming or manually intensive.
In this post, we’ll walk through 3 specific examples of how teams can use Labelbox to accelerate labeling projects by using GPT-4V to create high-quality labels for various data types, including images, HTML, and text.
Generating high-quality datasets is often one of the most tedious parts of the development process for ML teams. By using Labelbox Foundry, ML teams can now quickly use LLMs to their advantage to pre-label or enrich data that span a wide range of use cases, such as identifying amenities for rental listings, classifying items in a product catalog, or categorizing support messages.
Pre-labeling Use Case #1: Classifying amenities
Online travel marketplaces such as Expedia, Booking.com, Airbnb, VRBO, etc., often show product listings that have a main image with additional images as supplements. These travel marketplaces can enhance their user experience and conversion rates by enriching objects and desired characteristics in product listings to give users more context about visual assets.
As an example of this in action, we’ve seen ML teams upload primary and supporting images as a single entity, referred to as a data row. A data row can be considered as a task that a human or AI can do. Afterwards, the ML team will tap into Foundry, which helps automate labeling tasks.
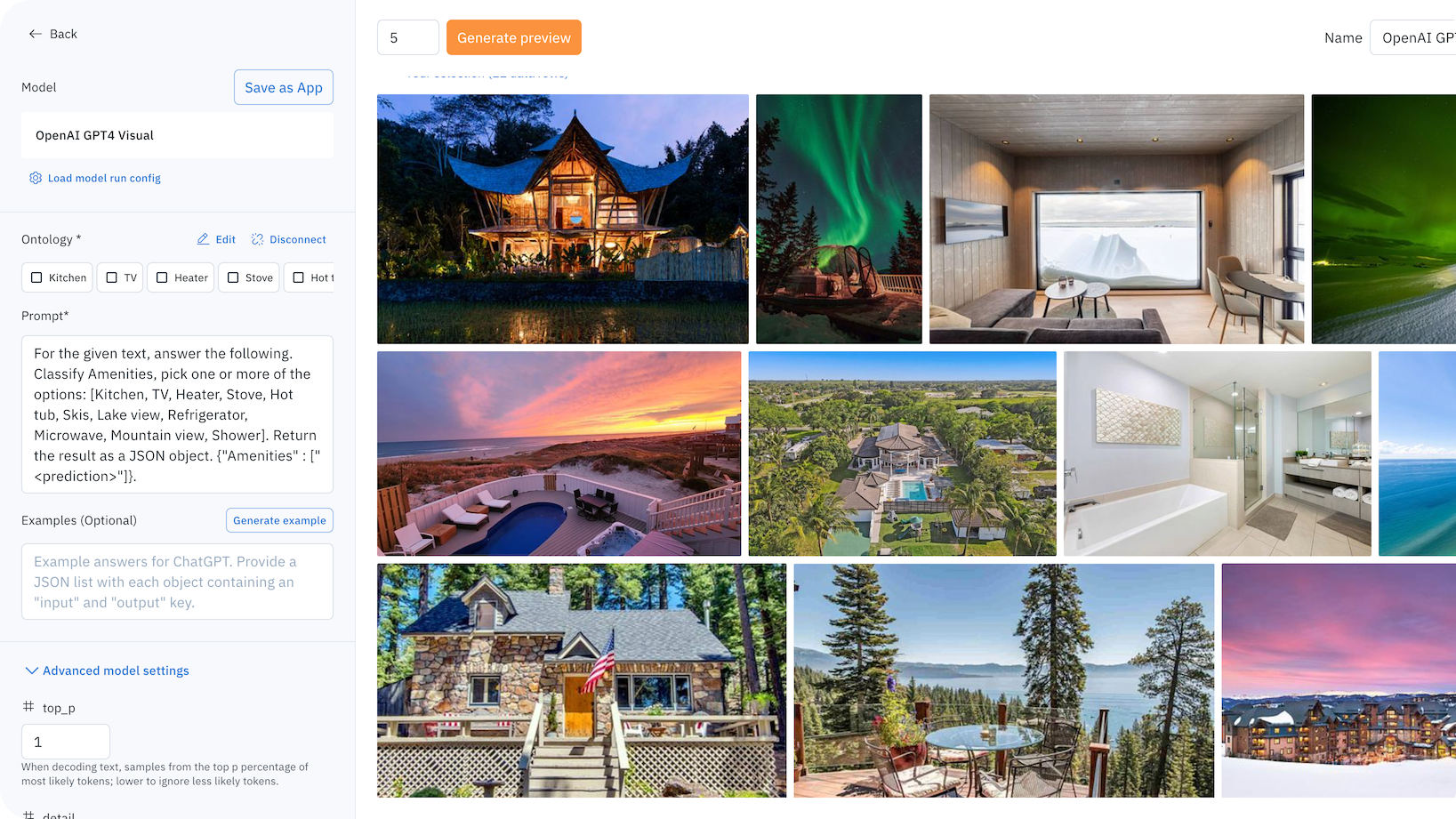
The example below focuses on identifying various amenities in a rental listing.

Step 1: Select images and choose a foundation model of interest
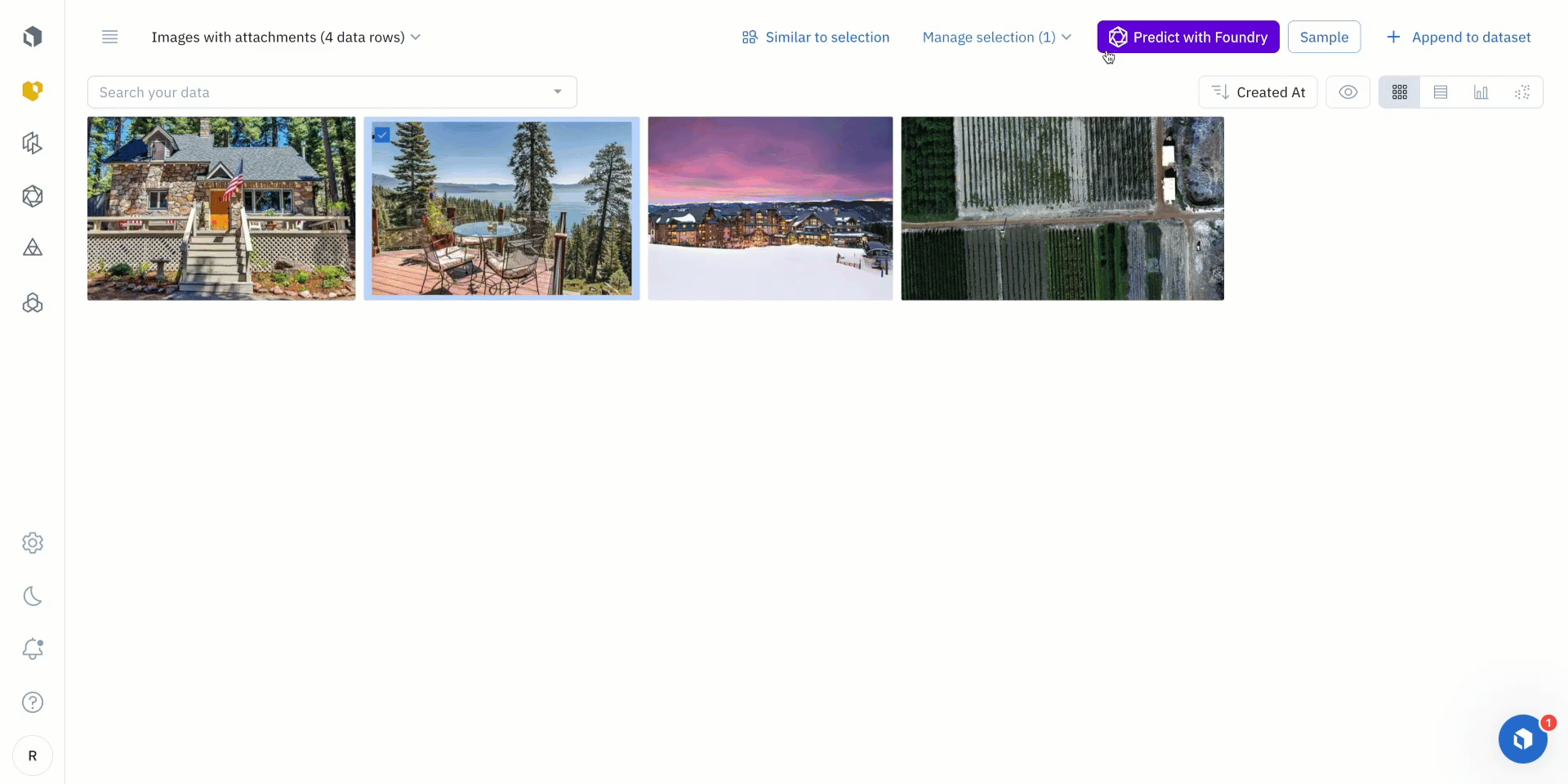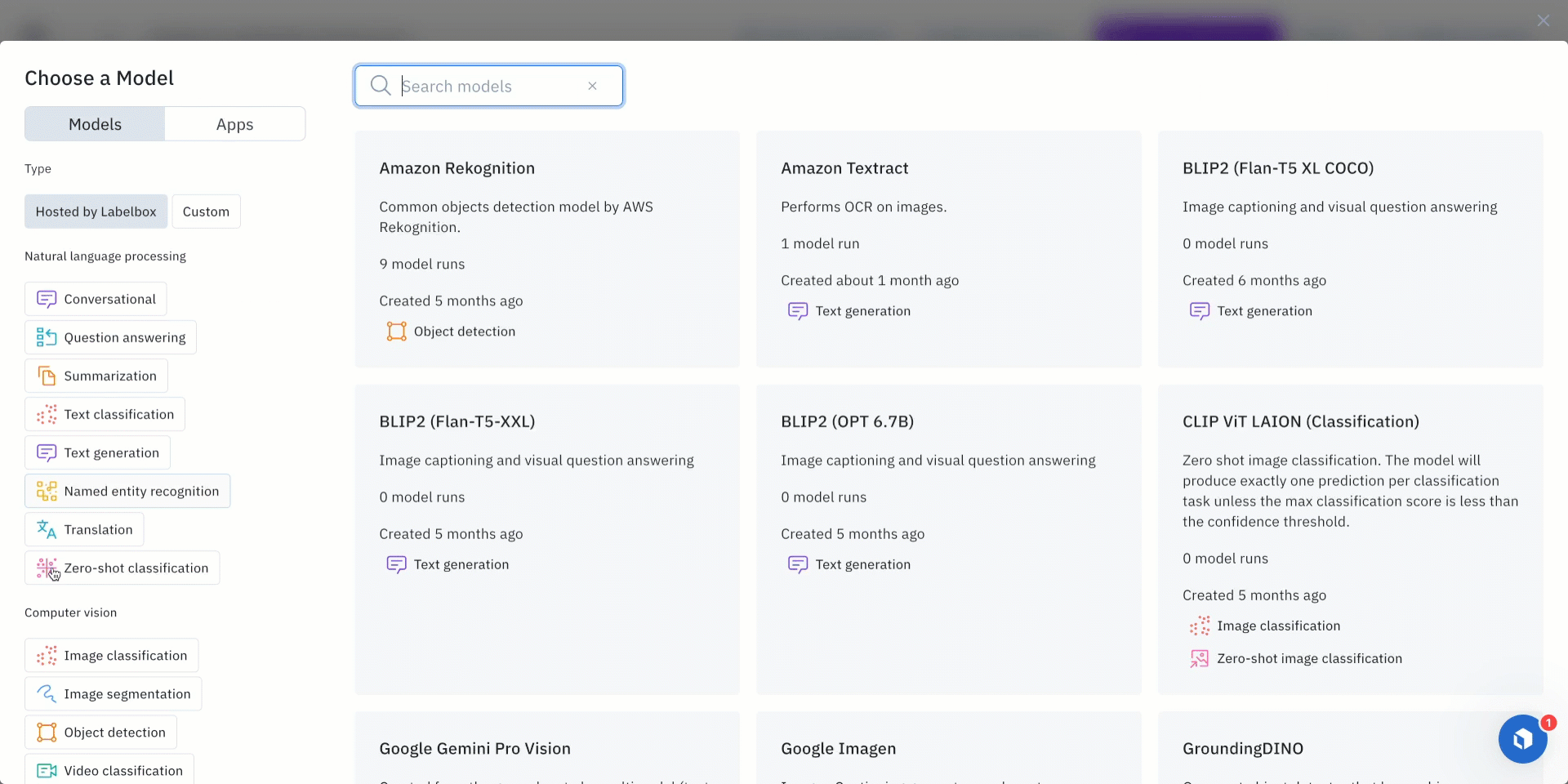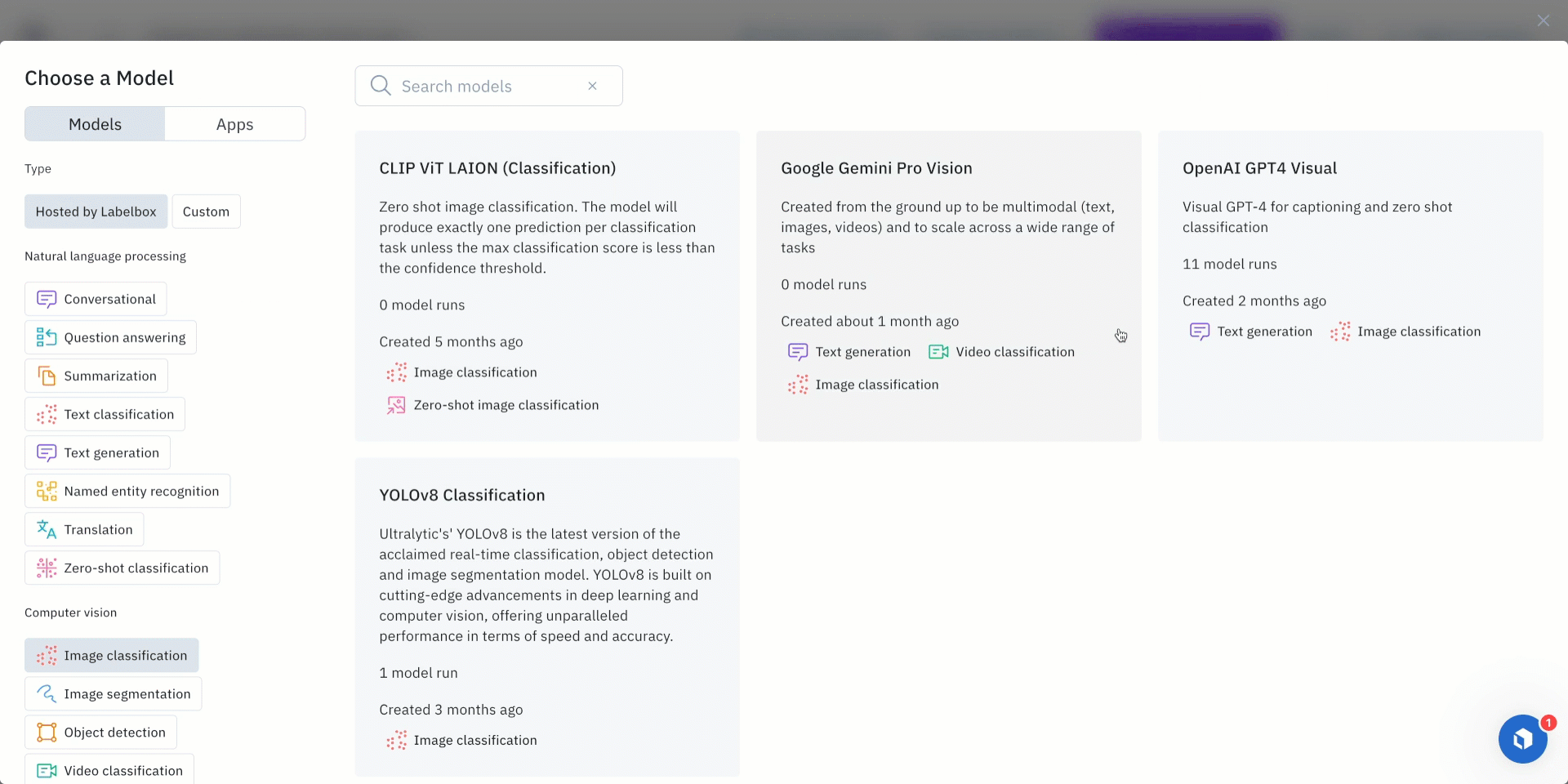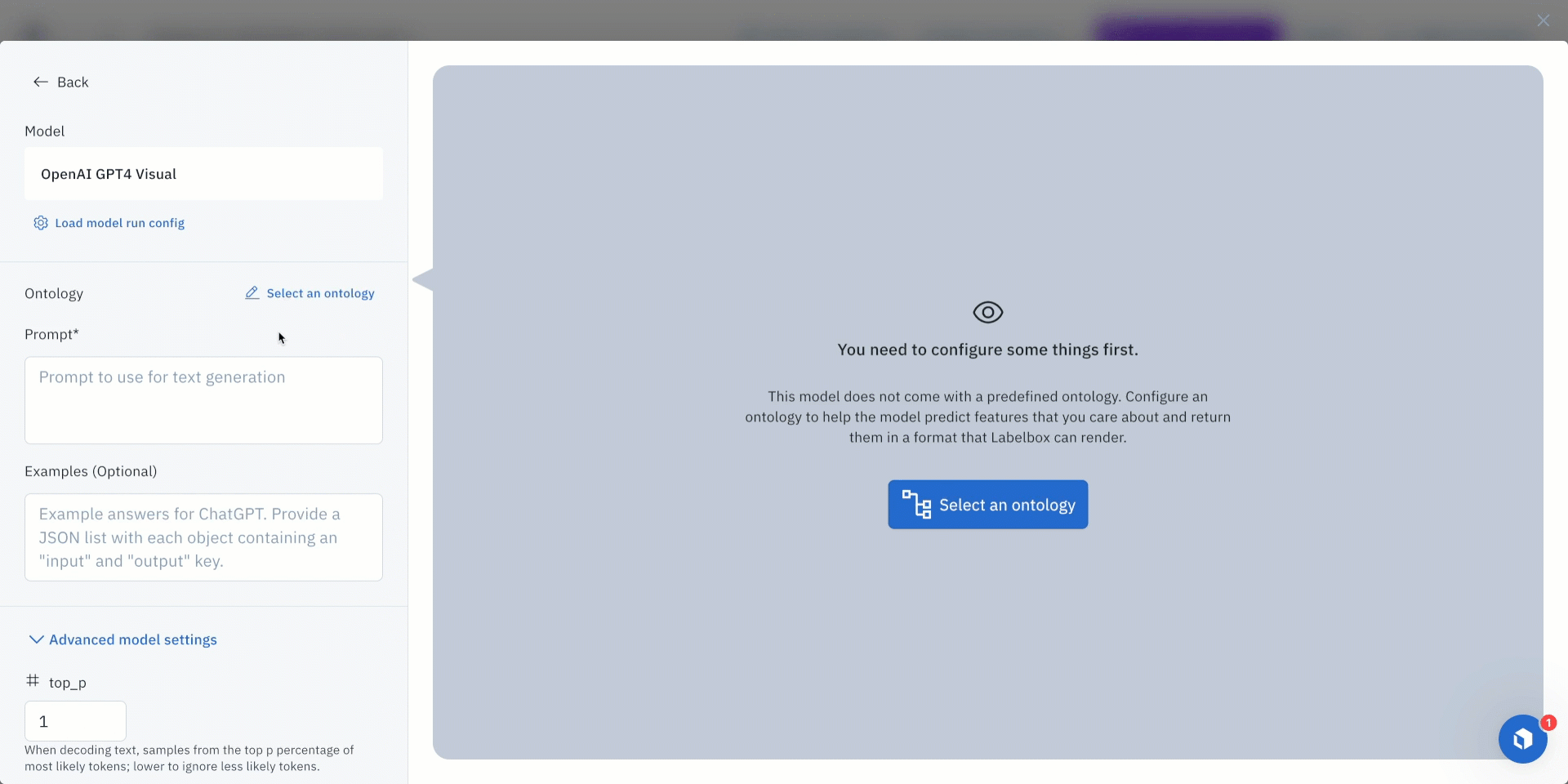
- To narrow in on a subset of data, users can use Labelbox Catalog filters, including media attributes, a natural language search, and more, to refine the images on which the predictions should be made.
- Users can then click “Predict with Model Foundry” once the data of interest has appeared.
- Users will then be prompted to choose a model of interest for a model run.
- Select a model from the ‘model gallery’ based on the type of task - such as image classification, object detection, and image captioning.
- To locate a specific model, users can browse the models displayed in the list, search for a specific model by name, or select individual scenario tags to show the appropriate models available for the machine-learning task.
Step 2: Configure model settings and submit a model run

Once the model of interest is selected, users can click on the model to view and set the model and ontology settings or prompt.
- Each model has an ontology defined to describe what it should predict from the data. Based on the model, there are specific options depending on the selected model and your scenario. For example, you can edit a model ontology to ignore specific features or map the model ontology to features in your own (pre-existing) ontology.
- Each model will also have its own set of settings, which can be found in the Advanced model setting. For this use case, the only Foundry model setting I changed was to select “use_image_attachments” to pass the supporting images to GPT-4V.
- Users can then generate preview predictions on up to five data rows to understand how the current model settings affect the final predictions.
While this step is optional, generating preview predictions allows users to confirm the configuration settings confidently:
- If users are unhappy with the generated preview predictions, they can edit the model settings and continue to generate preview predictions until they're satisfied with the results.
- After users are satisfied with the preview predictions, a model run can be submitted.

Prompt used for Amenities classification:
- You are a helpful assistant. What amenities are in the images? Respond with the following options. [Kitchen, TV, Heater, Stove, Hot tub, Skis, Lake view, Refrigerator, Microwave, Mountain view, Shower]. Return the result as a dictionary. {“Amenities” : [“<prediction>”]}
Step 3: Send the images to Annotate
Users can transfer the results to a labeling project using the UI via the "Send to Annotate" feature. Labelers can then quickly review labels for accuracy.

Pre-labeling Use Case #2: Recommendation engine
E-commerce companies such as Amazon, Wayfair, Etsy, and eBay offer a "similar products" feature that improves the discoverability of products and provides an easy way to compare items, thereby increasing customer satisfaction and reducing return rates.
A recommendation engine often powers the product similarity feature that requires integrating text and images into a unified file. ML teams can use Labelbox to help automate this workflow as we support HTML files that state-of-the-art models can label or enrich. For the HTML product similarity task, the initial steps 1-2 remain the same, but the prompt and ontology will be adjusted to focus on classifying whether the products are identical, and GPT-4V will provide reasoning.
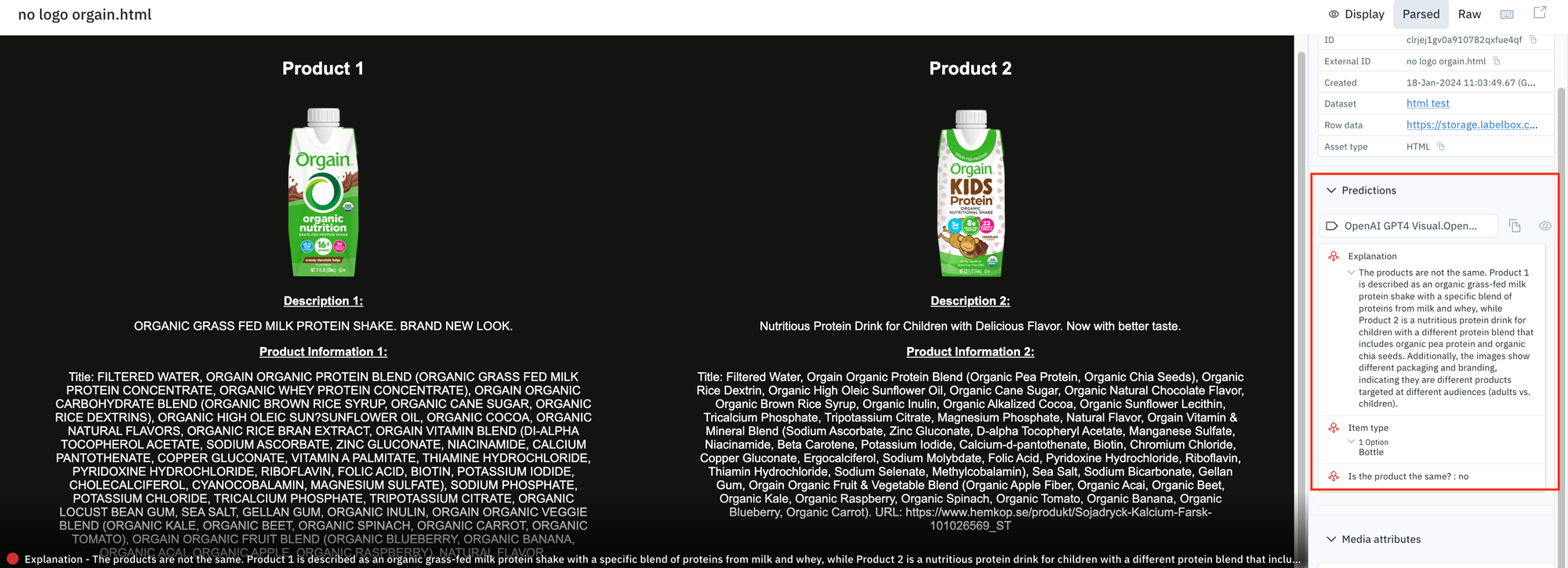
Prompt used for recommendation engine:
- You are a helpful assistant. Based on the descriptions and images provided for the two products, determine whether the products being described are the same.
- Classify Is the product the same? pick one of the options: [yes, no].
- Classify Item type as the following: [Food, Perishable, Liquid, Bottle, Nonperishable].
- Answer Explanation with why yes or no.
- Return the result as a JSON. {"Is the product the same?" : "<prediction>", "Item type" : ["<prediction>"], "Explanation", "<prediction>"}
Pre-labeling Use Case #3: Support chat classification
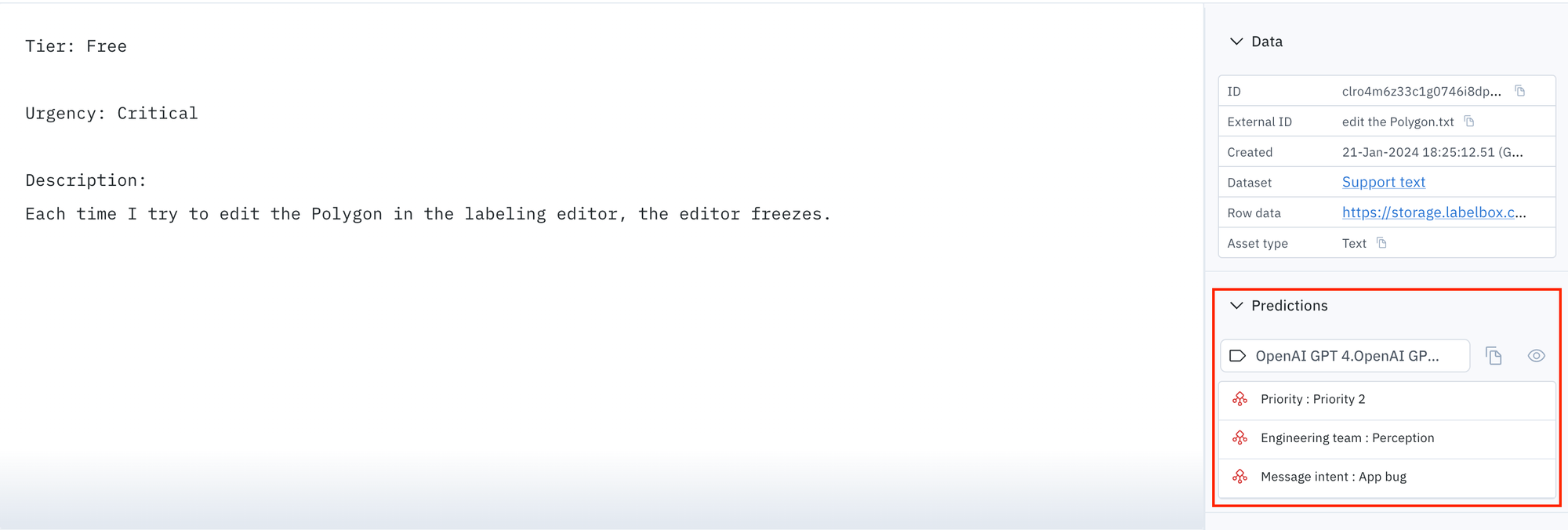
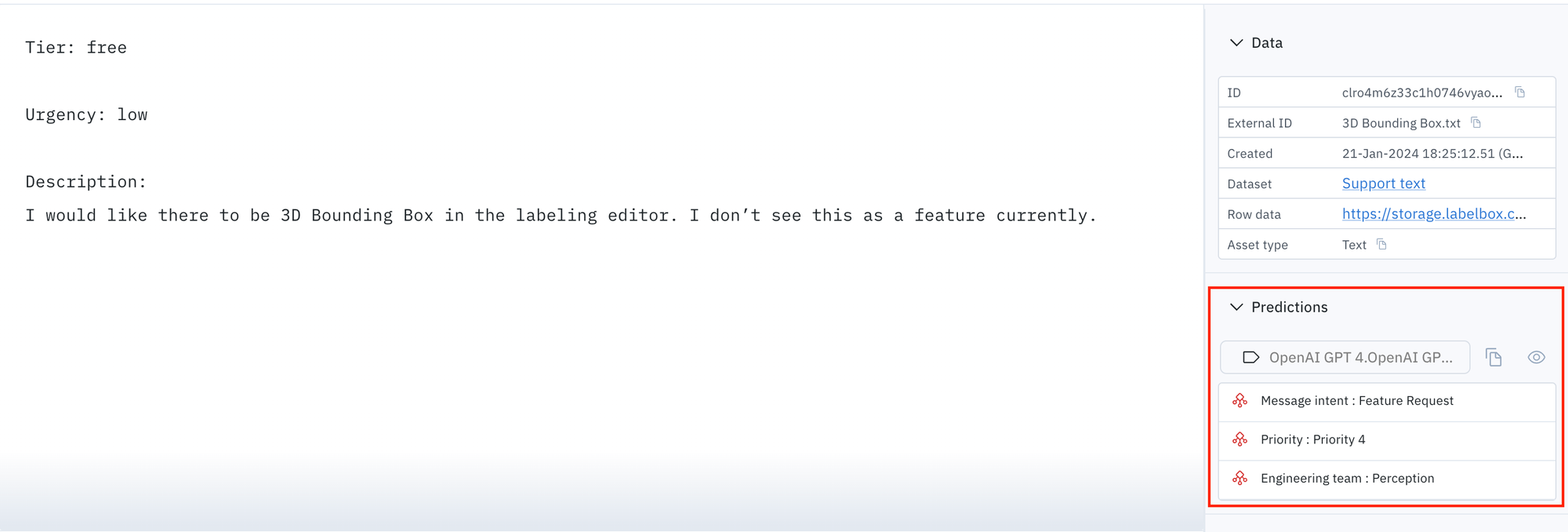
Enterprises with a significant user base require a full-fledged customer support team to ensure smooth operations. Providing efficient customer support is typically achieved by efficiently categorizing and triaging high volumes of real-time support messages.
However, support teams often have to manually classify tickets, which can be time-consuming and prone to human error. This process is necessary to sort the messages into the correct reporting categories and identify which engineering teams should handle which bugs.
By using advanced large language models (LLMs) such as GPT-4V, customer chat intent classification can be automated, and then labelers can review and edit the labels if needed.
The following prompt was used to classify customer messages, and default Foundry model settings were used. If GPT-4V fails to produce an expected answer, users can add an if statement to capture the edge cases, as shown below.
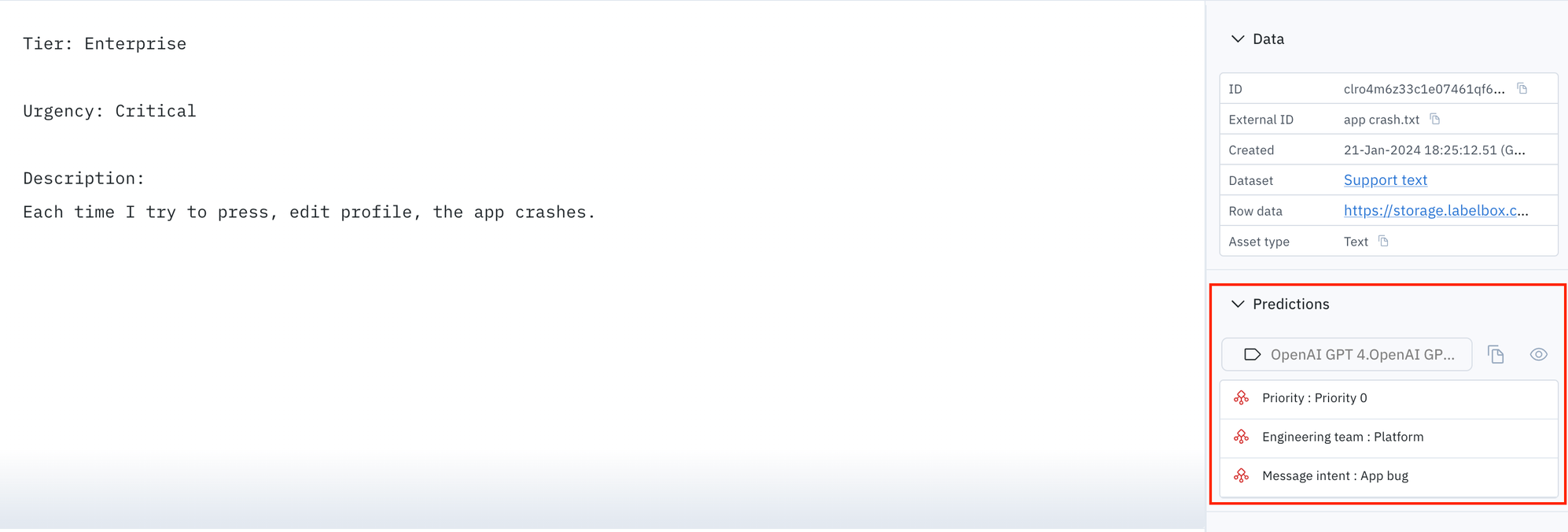
- You are a helpful support assistant. Read the following text and classify them to the information below.
- If the tier is Enterprise and urgency is Critical then Priority is Priority 0.
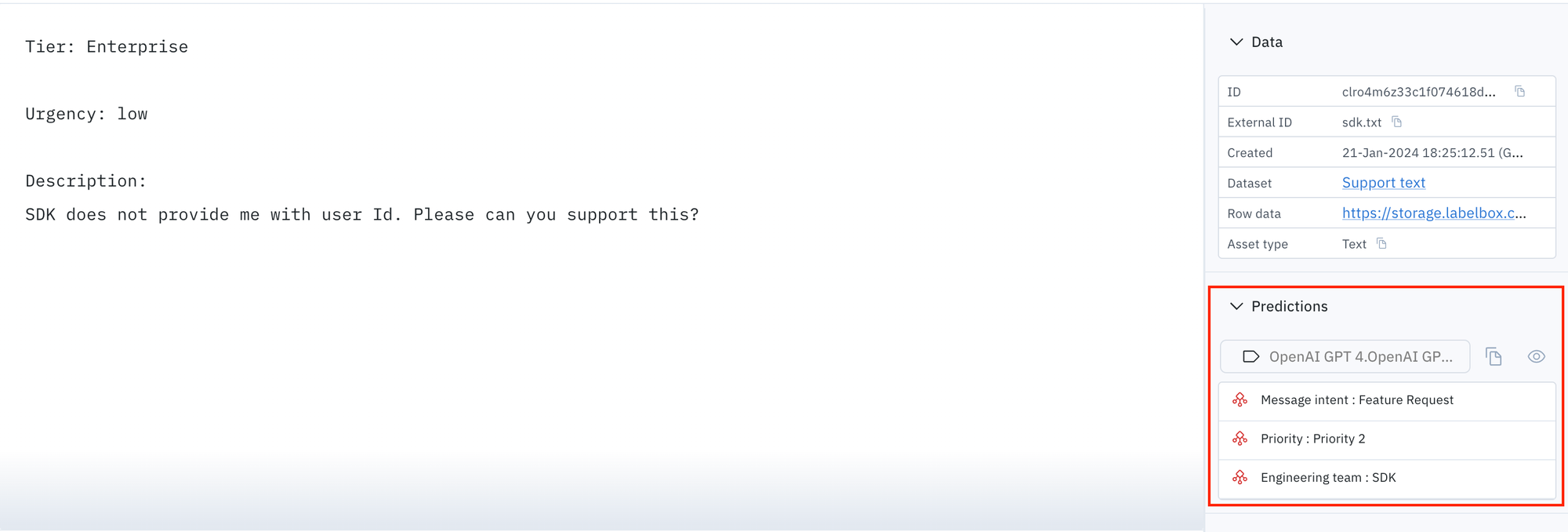
- If the the ticket is related to feature request and Tier is Enterprise then Priority is P2. Otherwise all feature request tickets are P4.
- If the tier is Free and urgency is low, then Priority is Priority 4.
- If description is related to python or coding then engineering team is SDK.
- If description is related to labeling editor then engineering team is Perception.
- If description is related to log in issues or app crashes then engineering team is Platform.
- If urgency is critical and tier is not enterprise then priority should be Priority 2.
- If description is stating to support a feature then that is a feature request.
Classify Message intent, pick one of the options: [Accidental payment, Unauthorized payment, Irrelevant, Unable to login, Reset password, Cancel subscription, App bug, Feature Request]. Classify Priority, pick one of the options: [Priority 1, Priority 2, Priority 3, Priority 4, Priority 0]. Classify Engineering team, pick one of the options: [SDK, Perception, Platform].
Additional Considerations
Additional considerations as users incorporate Foundry labels into their projects and workflows:
- Incorporating human evaluators to find edge cases and updating the prompt would give the best results as users create more labels with Foundry. For example, if statements were added in the chat classification use case to account for edge cases.
- Users can also A/B test different models from Foundry to find the model that best fits the use case using Labelbox Model.
- In addition to GPT-4V, users can utilize various state-of-the-art models like Gemini 1.5 Pro, Claude 3 Opus, and more from Labelbox Foundry, as seen here.
- If we do not currently support your use case or any questions arise, feel free to contact our support team, as we would love to hear your feedback to improve Foundry.
Conclusion
Large Language Models (LLMs) and generative AI are showing an enormous impact on the individual productivity of knowledge workers. As these large foundation models improve, we’ll continue to see impressive real-world use cases for automating pre-labeling more quickly and cheaply. Completing labeling projects with Labelbox Foundry combines both AI-assistance and human-in-the-loop workflows to automate one or more specific tasks.
Check out our additional resources on how to utilize state-of-the-art AI models in Foundry, including using model distillation and fine-tuning to leverage the power of foundation models:


