
 All blog posts
All blog postsMikiko Bazeley•January 23, 2024
A pragmatic introduction to model distillation for AI developers
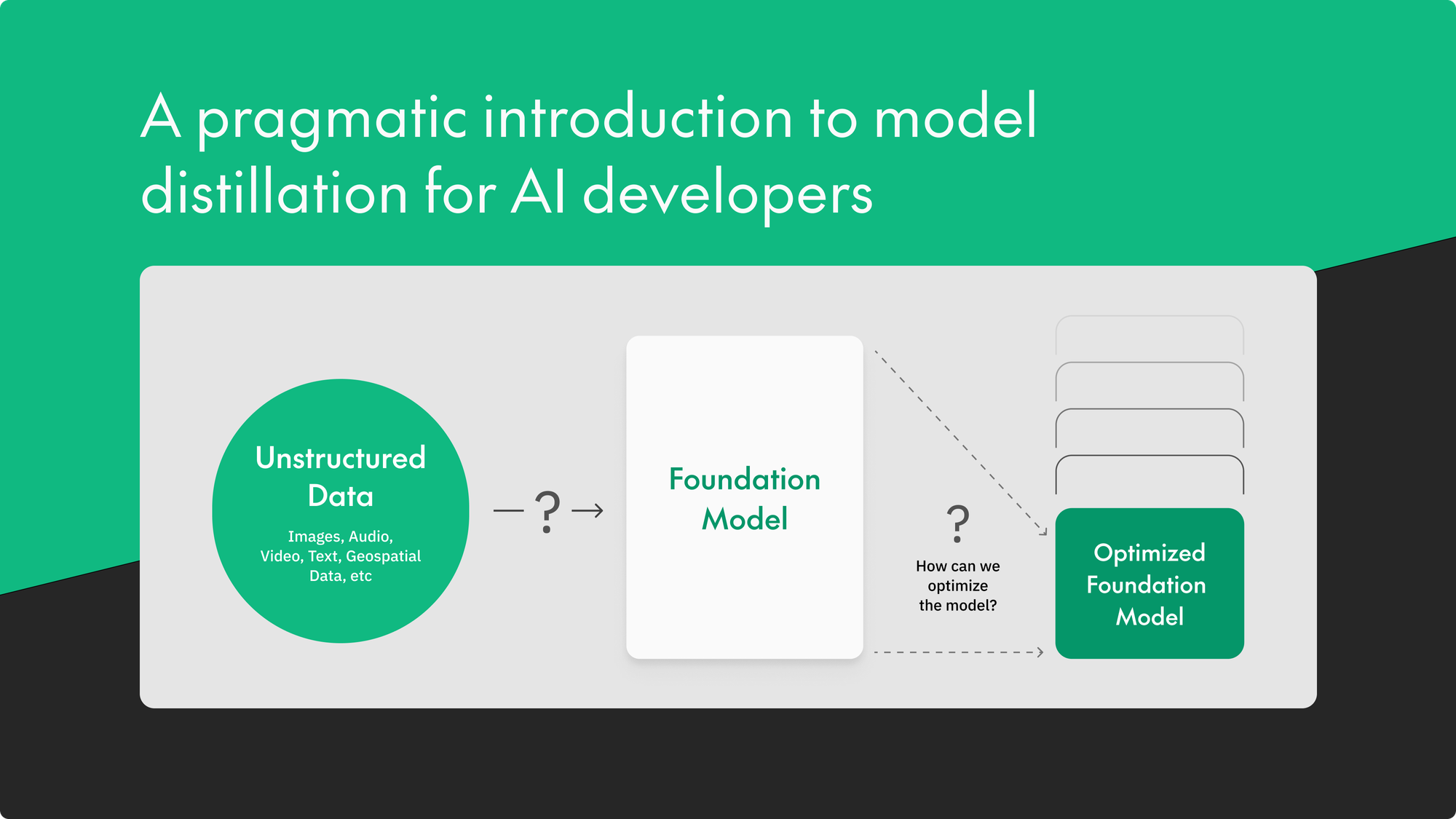
The landscape of artificial intelligence (AI) and machine learning (ML) is continuously evolving, surfacing innovative techniques that revolutionize how we develop and deploy AI models.
One such technique gaining significant traction is model distillation.
Model distillation has been instrumental in driving both open-source innovation of LLMs as well as the adoption of large models (both language and vision) for use cases where task specificity and runtime optimization have been required.
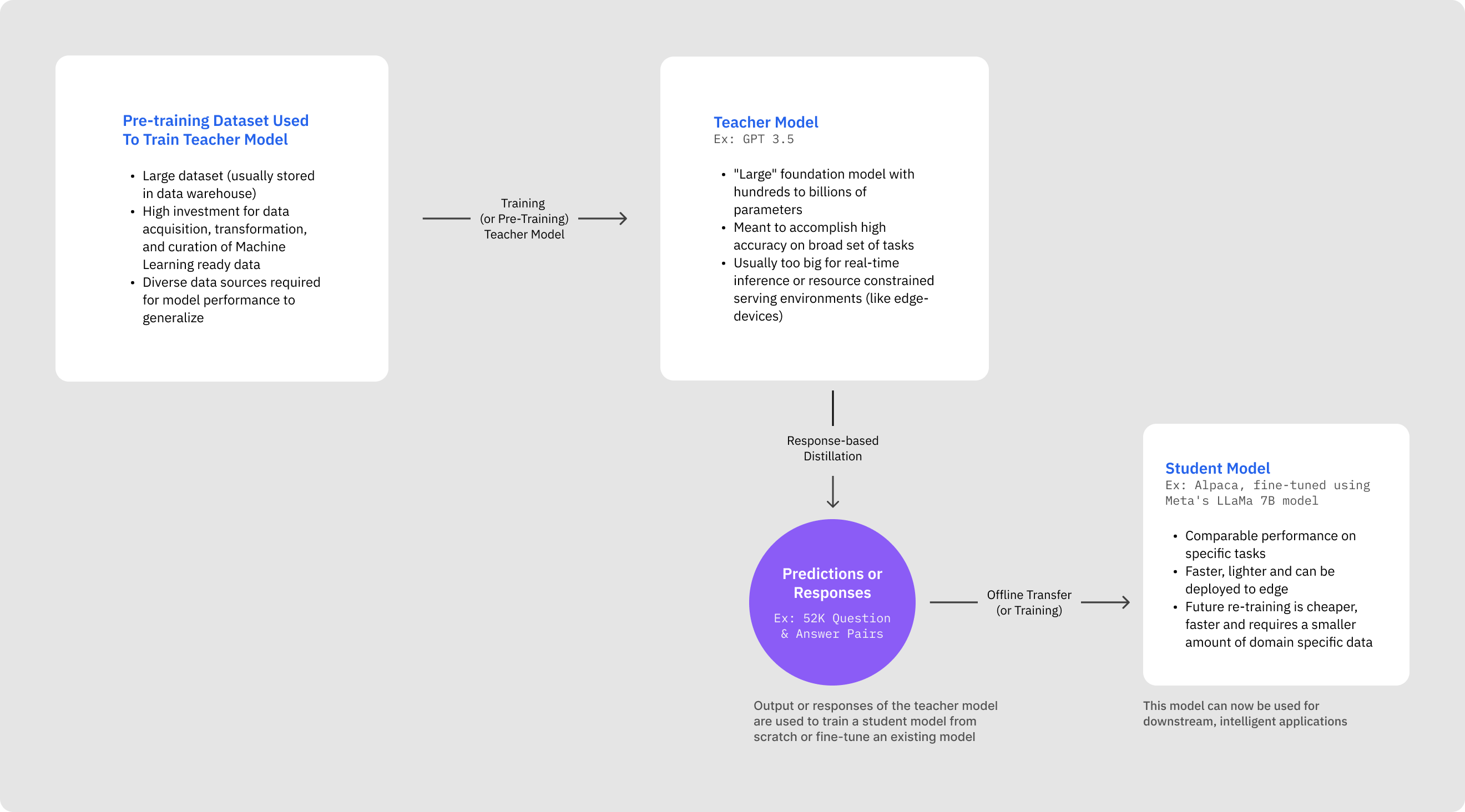
One of the most well-known examples of model distillation in action is Stanford’s Alpaca, based on Meta’s LLaMa 7B model.
Alpaca was trained in less than 2 months for less than $600 on 52K question and answer pairs generated using OpenAI’s text-davinci-003. At the time of release Alpaca boasted near comparable performance to GPT 3.5.
Although Alpaca was deprecated, the ability for a small team to create impressive models for a fraction of the cost from large foundation models injected fuel in the ensuing months for developers and teams eager to fine-tune their own powerful, task specific models using open-source models.
In this blog post our goal is to provide a pragmatic introduction to model distillation.
Model distillation is a useful technique that we believe will stand the test of time for companies wanting to efficiently and effectively create the best models for their use cases.
We’ll provide the “why” and introduce the “how” of performing model distillation so that you too can train powerful and efficient models, important components of intelligent applications.
If you’re an AI developer struggling to adopt Large Language or Large Vision models and trying to understand where model distillation fits in with other techniques like RAG, fine-tuning, and dataset distillation, this is the guide for you.
Introduction
A Brief Overview
Model distillation, also known as knowledge distillation, is a technique that focuses on creating efficient models by transferring knowledge from large, complex models to smaller, deployable ones.
We can think of the typical process as taking the best of a wide, deep model and transferring it to a narrow, short model.
This process aims to maintain performance while reducing memory footprint and computation requirements, a form of model compression introduced by Geoffrey Hinton in "Distilling the Knowledge in a Neural Network" (2015).
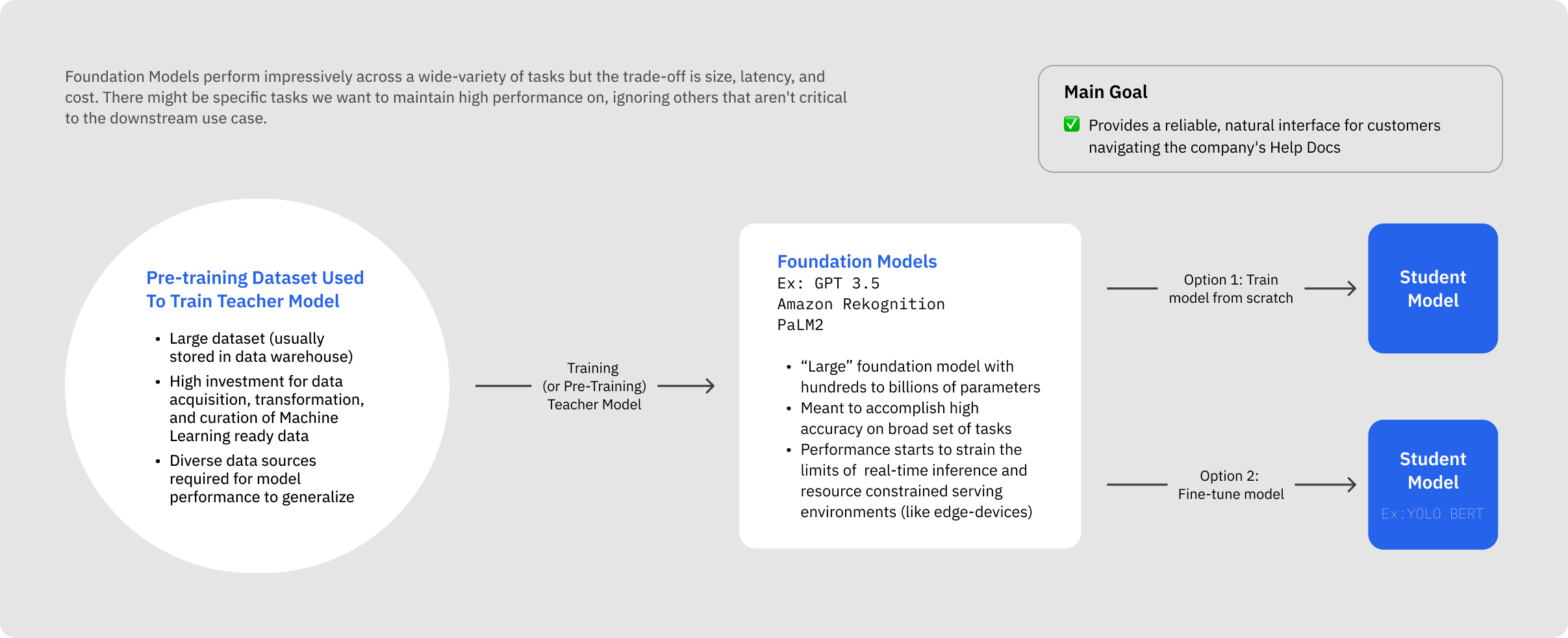
Why Customize Foundation Models
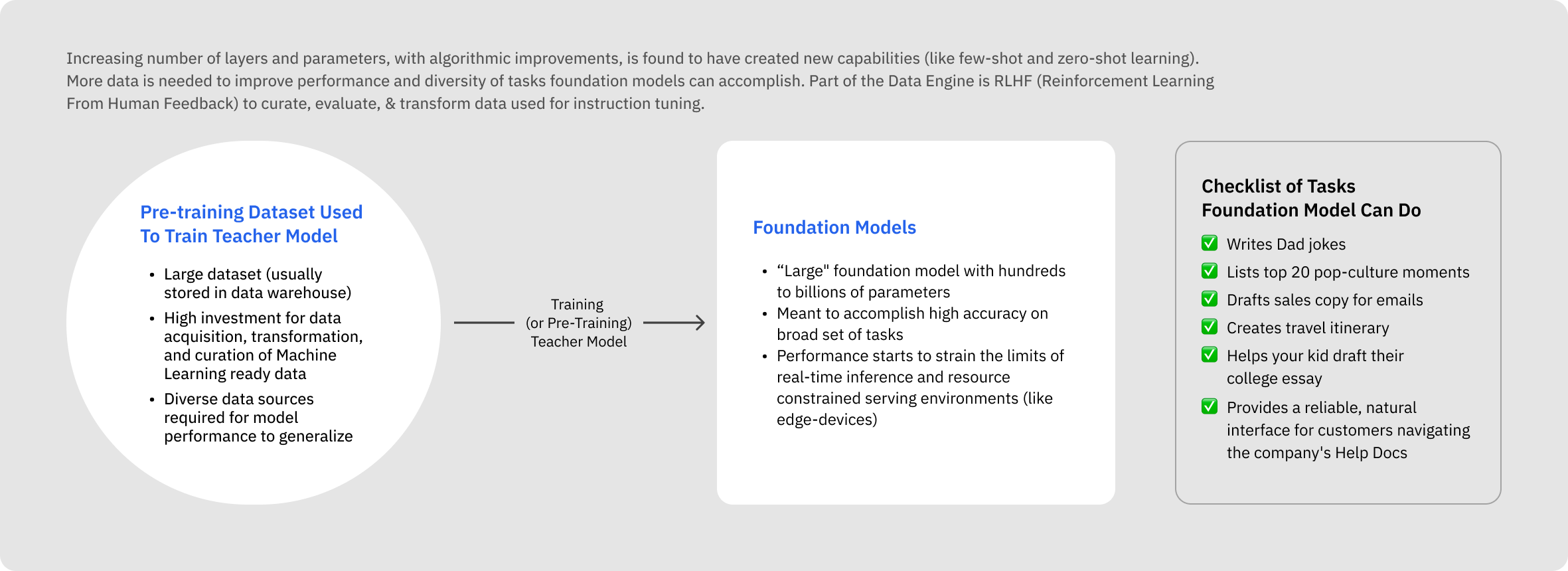
Despite the high accuracy of foundational models and ability to perform remarkable feats of zero-shot learning, their deployment often faces challenges like increased latency and decreased throughput performance.
As a result, large language models (LLMs) with their millions of parameters, are cumbersome and resource-intensive, making them impractical for teams needing near real-time solutions beyond public benchmarks.
For example, Google gives the estimate that a “single 175 billion LLM requires 350GB of GPU memory”. Many of the most powerful LLMs can be upwards of 170 billion parameters and even LLMs with 10 million parameters will require 20GB of GPU memory (assuming a roughly 2:1 ratio of GPU memory requirements for serving and the number of parameters). This tension necessitates the development of smaller, more specialized models.
Model distillation emerges as a solution (especially for companies that have unique and proprietary data), offering efficient deployment, cost reduction, faster inference, customization, and sustainability.
By optimizing foundation model sizes, foundation models can become even more widely adopted across a broader, diverse set of use cases in a practical, cost-effective, and environmentally friendly manner.
Understanding Model Distillation
Definition and Basic Concepts
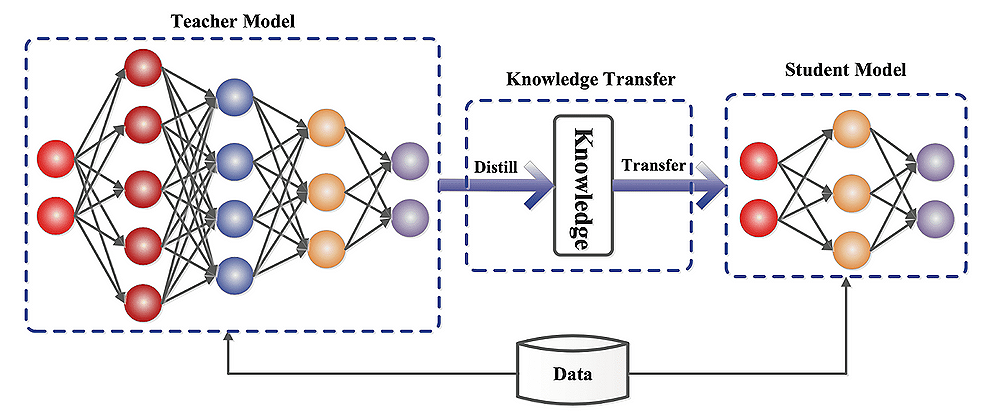
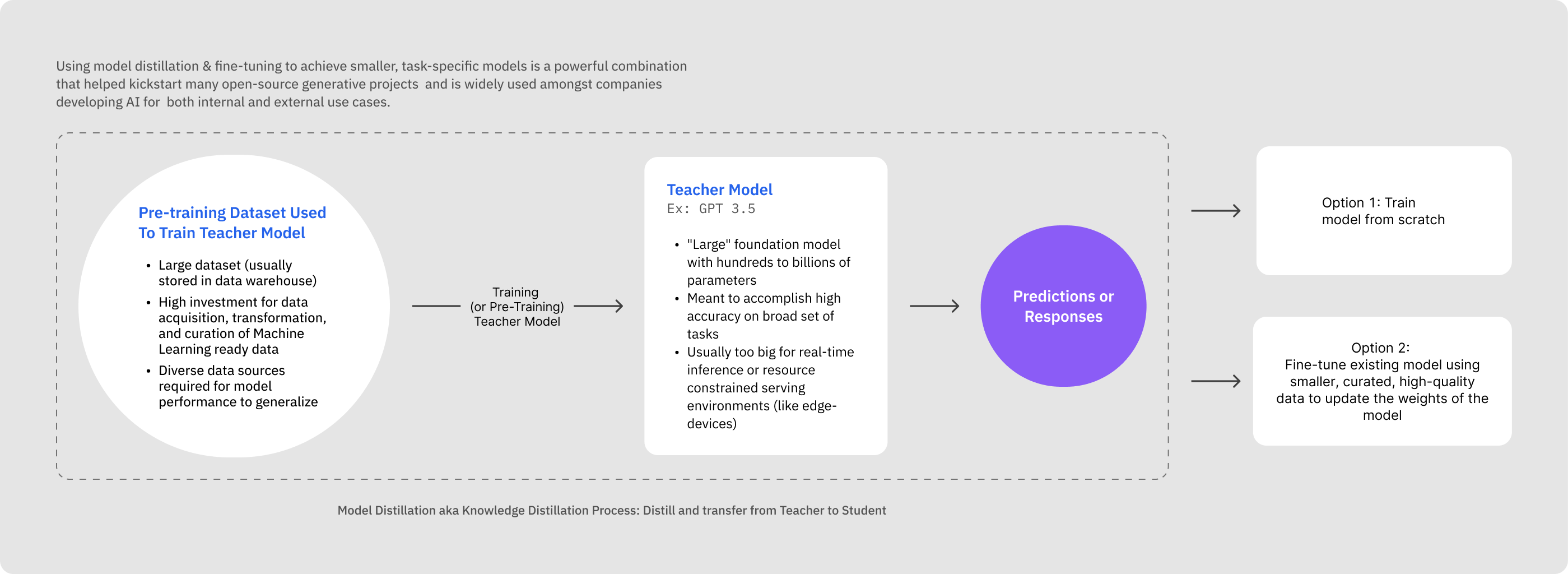
Earlier we described model distillation as a process of transferring knowledge from a large, complex model (teacher) to a smaller, more efficient model (student).
This (usually) involves two separate models: the teacher model, large and highly accurate, and the student model, compact and less resource-intensive.
Key Components of Model Distillation
Let’s dig in deeper to the different components involved in model distillation.
There are a couple key decisions that need to be made, such as:
Picking Teacher and Student Model Architectures
Model distillation involves two main elements: the teacher model, a large pre-trained model with generally high performance, and the student model, a smaller model that learns from the teacher (and that will ultimately be used for downstream applications).
The student model can vary in structure, from a simplified or quantized version of the teacher model to an entirely different network with an optimized structure.
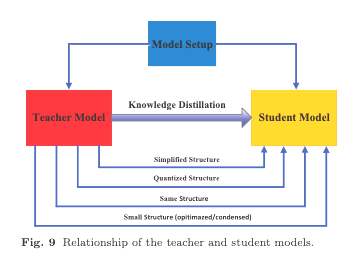
The Distillation Process Explained
The next decision to be made is the distillation process to use.
The distillation process involves training the smaller neural network (the student) to mimic the behavior of the larger, more complex teacher network by learning from its predictions or internal representations.
This process is a form of supervised learning where the student minimizes the difference between its predictions and those of the teacher model.
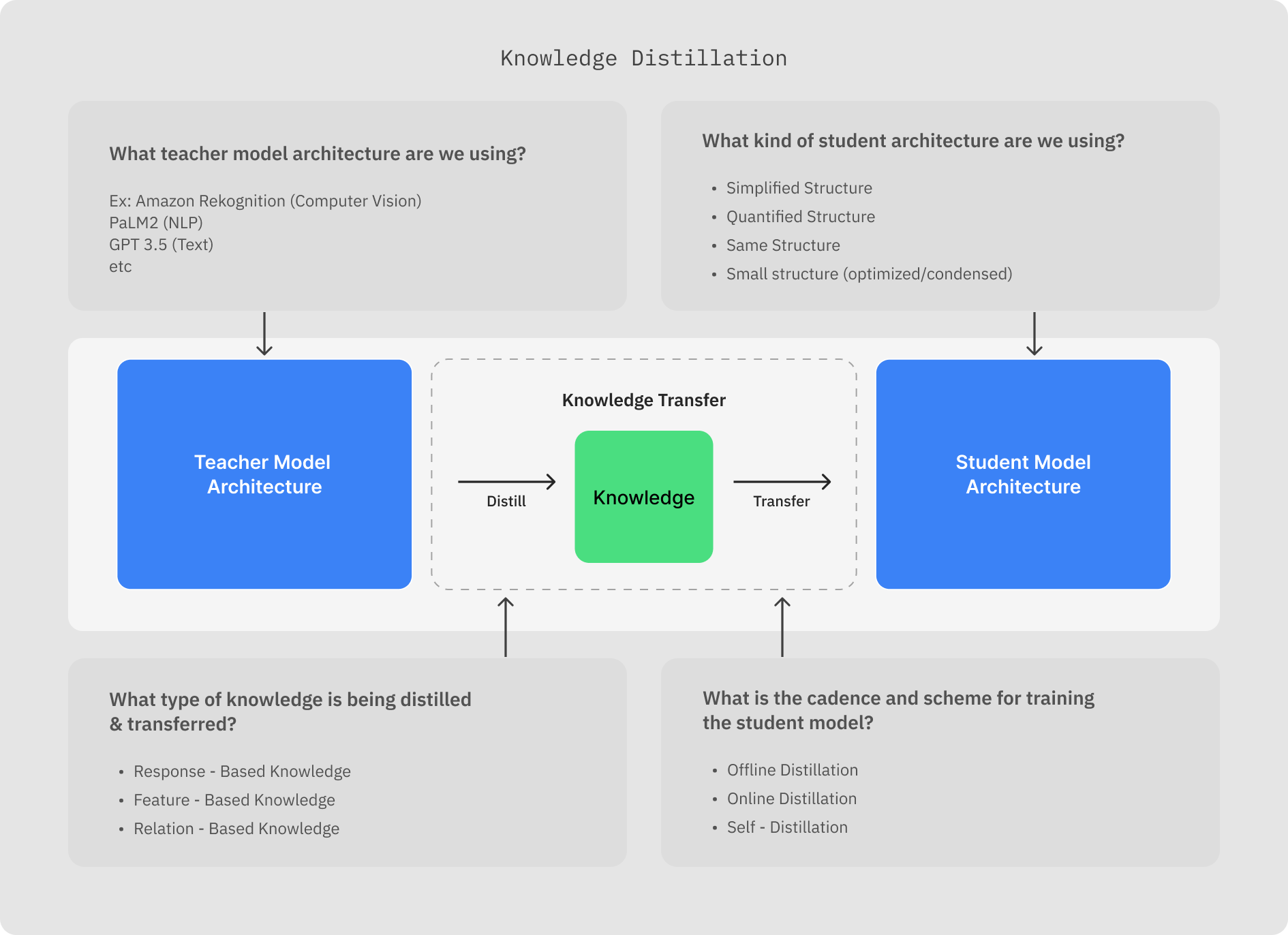
Distillation Knowledge Types
What do we mean by knowledge?
The types of knowledge distillation can be categorized into three types: response-based, feature-based, and relation-based distillation.
Each type focuses on different aspects of knowledge transfer from the teacher to the student model and offers unique advantages and challenges.
Although the most common and easiest form of knowledge distillation to get started with is response-based distillation, it’s helpful to understand the different types of knowledge distillation.
1. Response-Based Distillation: Focuses on the student model mimicking the teacher's predictions. The teacher generates soft labels for each input example, and the student is trained to predict these labels by minimizing the difference in their outputs.
- Pros: Easy implementation, applicable to various models and datasets.
- Cons: Only transfers output-related knowledge, doesn’t capture complex internal representations.
2. Feature-Based Distillation: Involves the student model learning the internal features or representations learned by the teacher. The process includes the student minimizing the distance between the features learned by both models.
- Pros: Helps learn robust representations, applicable across tasks and models.
- Cons: Computationally expensive, not suitable for tasks where teacher's internal representations aren't transferable.
3. Relation-Based Distillation: This method teaches the student to understand the relationships between inputs and outputs. It involves transferring the underlying relationships between these elements from the teacher to the student model.
- Pros: Enables learning robust and generalizable input-output relationships.
- Cons: Computationally intensive, requires greater sophistication and experience for implementation by the ML engineer.
Training Methods
The final decision that needs to be made is the training method used to transfer knowledge from the teacher to the student models.
There are three main training methods in model distillation: offline, online, and self-distillation.
Offline distillation involves a pre-trained, frozen teacher model, while online distillation trains both teacher and student models simultaneously.
Self-distillation uses the same network as both teacher and student, addressing conventional distillation limitations. This method requires the ability to copy the teacher model and be able to update the model, which is not possible with proprietary models or models where the weights and architecture haven’t been published.
Knowledge of different training methods (offline, online, self-distillation) is essential for AI developers who need to implement and manage the training process in a way that aligns with their project's constraints and goals.
For instance, an AI developer working in an environment with limited data availability might find self-distillation methods particularly useful.
Most teams however start with a form of response-based, offline distillation. Training offline allows the ML Engineer to evaluate model performance and analyze model errors before deploying the student model to production.
Benefits of Model Distillation
There are many benefits to performing model distillation and using smaller, task specific models rather than a Large Language Model (or Large Vision Model) out of the box.
Efficiency in Training
Model distillation enhances data efficiency, requiring less data for pretraining (and potentially fine-tuning). Model distillation aligns with data-centric AI philosophy to maximize the utility of data.
Efficiency in Deployment
Distilled models are smaller and more efficient, ideal for deploying on platforms with limited resources. They offer versatility in applications like edge computing and real-time processing.
Performance Improvements
Similar to fine-tuning, model distillation can improve accuracy and performance on specific tasks and domains. The resulting smaller models achieve similar performance to larger ones but with quicker response times.
Resource Optimization
Model distillation leads to cost reduction and sustainability. It reduces computational and storage requirements, making it beneficial for projects with limited budgets and aligning with ethical AI development strategies.
Potential Challenges
Like many powerful techniques, key considerations must be made in order to effectively and efficiently implement model distillation as part of a team’s AI development process.
Some key challenges include:
- Selecting appropriate teacher and student models,
- Balancing size, speed, and accuracy of the student model,
- The technical complexity of the distillation process,
- Ensuring models are retrained as necessary to minimize model drift,
- Versioning and curating the data used for student training,
- Ensuring visibility and monitoring of the model performance.
Some teams in industries like gaming that require real-time learning or edge-constrained devices may find that offline training isn’t sufficient and they need to explore a continuous learning pattern of model development and deployment, such as online distillation.
Considerations In Using Model Distillation
Difference Between Model Distillation, Fine-Tuning, and Traditional Model Training
How does model distillation compare to fine-tuning, another popular technique utilized with foundation models? Are they mutually exclusive, complementary, or sequential approaches?
Model distillation, fine-tuning, and traditional model training (also called pretraining) each have distinct purposes in machine learning.
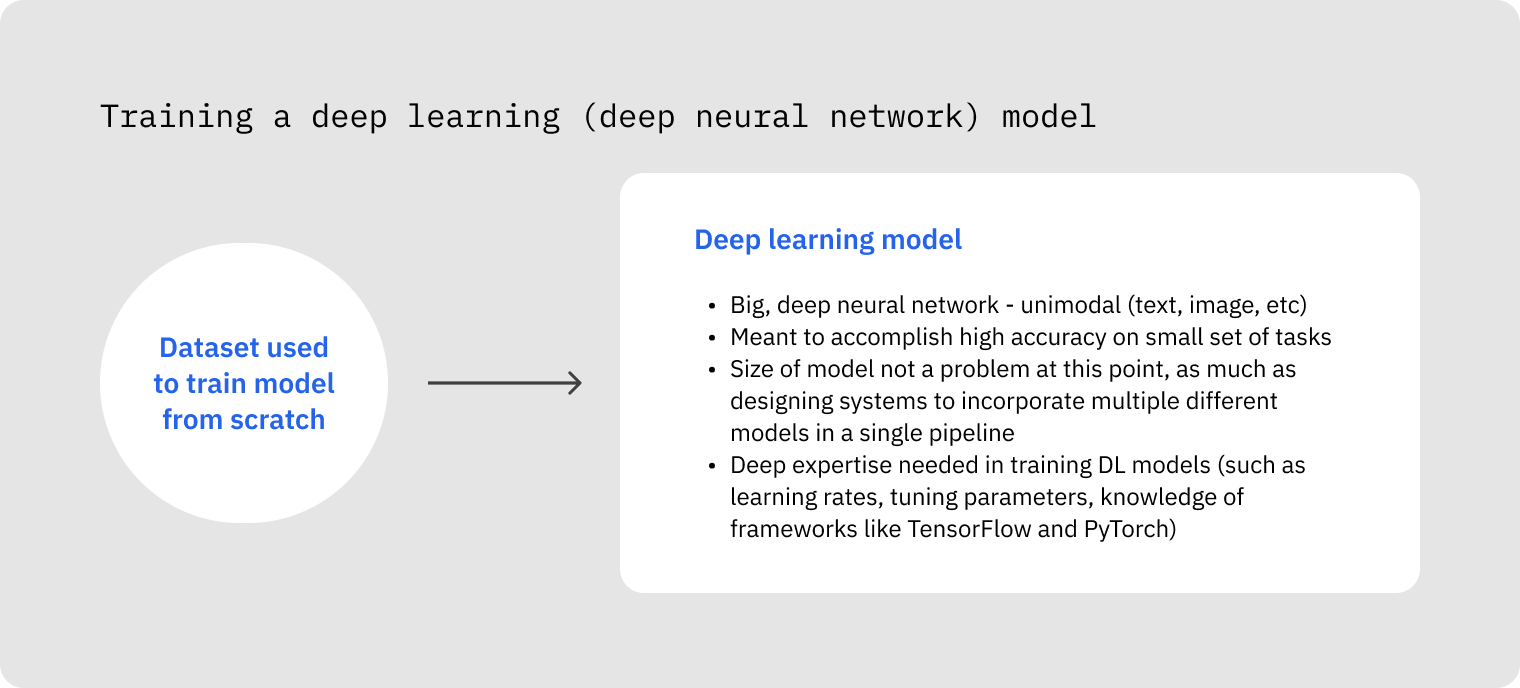
Traditional training involves learning directly from raw data, often requiring extensive resources, to generate a model from scratch. The drawback of this approach is the significant requirement for supporting Machine Learning Operations infrastructure to bridge the development-production chasm and the cost (both in data acquisition and compute) to approach the same performance of the foundation models available on the market (both proprietary and open-source).
Fine-tuning adjusts an existing, pre-trained model using a specific dataset, which can be resource-efficient but relies on human-generated labels. The resulting model is usually a similar size but with improved performance on domains and tasks corresponding to the dataset that was used.
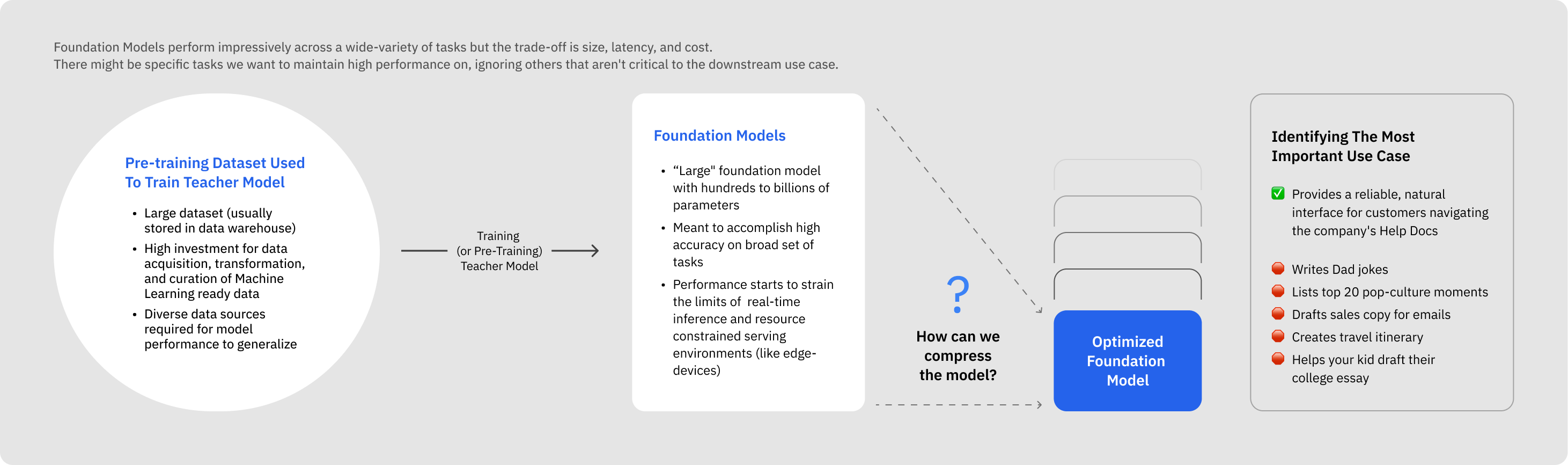
Model distillation offers the best of many worlds.
In comparison to pre-training (or traditional training), model distillation requires far less data (both raw and labeled). By starting with a powerful foundation model to train a smaller model (student), the developer is guaranteed a starting performance similar to the foundation model on specific tasks and domains but with less computational demand due to the smaller parameter size.
The offline, response-based approach for model distillation can be easily performed by a developer using minimal infrastructure and requires very little labeled data to start with, as the labels are provided by the parent mode in the form of a response. This approach is especially beneficial for deploying pipelines requiring the use of one or more foundation models in resource-constrained environments, as it bypasses the need for extensive data or manual labeling.
With that being said, the use of model distillation and fine-tuning isn’t mutually exclusive and can both be used by the same team and even for the same project.
You could perform model distillation using a base foundation model to create a smaller, student model from the parent model. Then the student model could be fine-tuned on a new, unique dataset (automatically transformed and ingested as part of a centralized, data catalog).
In upcoming tutorials, we show how easy it is to use Labelbox’s Model and Catalog to perform model distillation for both computer vision and NLP use cases.
Leveraging Model Distillation with RAG, Prompt Engineering, within FMOps
We’ve established that model distillation and fine-tuning are both used for the purpose of adapting the capabilities of large foundation models to more task specific use cases.
The ultimate purpose of model distillation is making models more inference-optimized as a form of model compression (without significant loss in performance and accuracy within the domain area of interest), whereas the focus of fine-tuning is improving task specific performance (with model size being relatively irrelevant).
In addition to knowledge distillation, other compression and acceleration methods like quantization, pruning, and low-rank factorization are also employed.
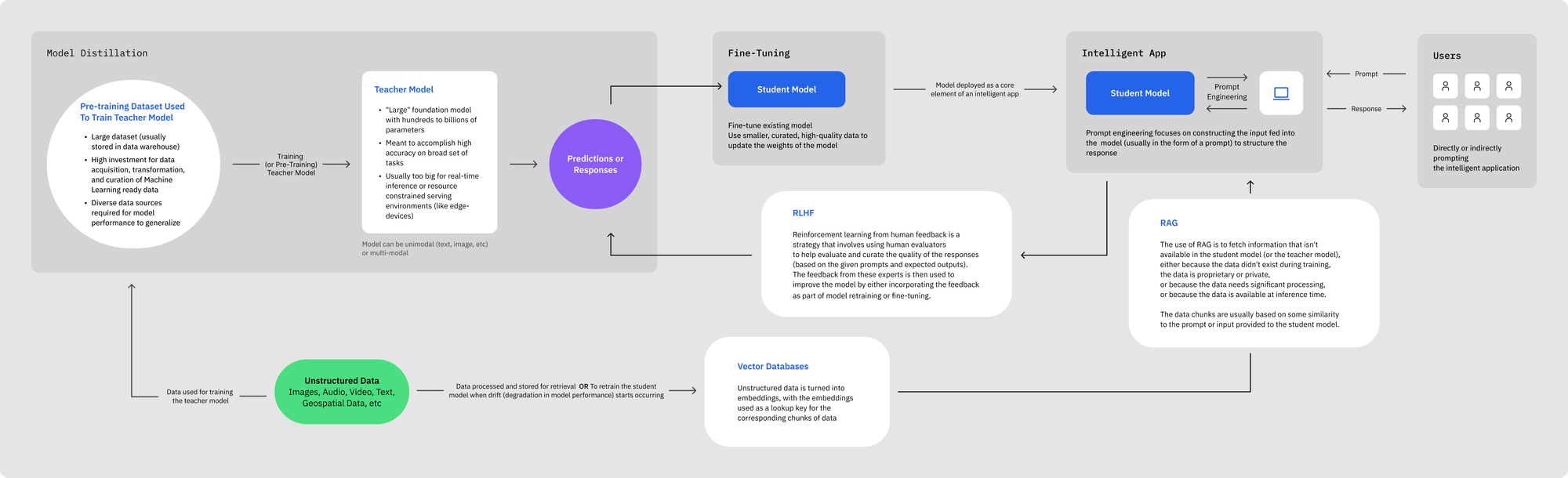
Model distillation can be used not just with fine-tuning but alongside RAG-based systems and prompt engineering techniques.
Model distillation, fine-tuning, RAG and prompt engineering are all considered important tools in the toolkit of FMOps, or Foundation Model Operations.
RAG-Based Systems
RAG (Retrieval-Augmented Generation) is a pattern (usually leveraging a vector database) that combines a neural retrieval mechanism with a sequence-to-sequence model, allowing it to retrieve relevant documents or data to enhance its responses. This approach enables the model to incorporate a broader range of external information and context, beyond what is contained in its initial training data.
In RAG-based systems, model distillation helps manage the size and complexity of models, ensuring they remain functional and efficient.
Similar to fine-tuning, model distillation produces a static model that doesn’t have real-time information on the entire internet. The resulting student model also shouldn’t have access to proprietary data.
RAG ensures that the right information is fetched and injected into the context of the prompt or as part of the response. In essence, RAG is usually pretty quick so the bottleneck in inference speed is usually in the embedding and serving stages (i.e. the student model).
Prompt Engineering
Prompt engineering involves crafting input prompts in a way that effectively guides models, especially foundation models based on natural language processing, to produce structured outputs or responses.
This process is crucial in optimizing the performance of models like GPT-3, as the quality and structure of the input significantly influence the accuracy and relevance of the generated output.
Prompt engineering should be used in generating the responses used to train the student model from the teacher model and to further structure the inputs and outputs to the student model once it’s deployed in production.
Reinforcement Learning From Human Feedback (RLHF)
Reinforcement Learning from Human Feedback (RLHF) is a machine learning approach where a model is trained to optimize its behavior based on feedback from human interactions, rather than solely relying on predefined reward functions. This method allows for more nuanced and contextually appropriate learning, as it incorporates human judgment and preferences into the training process.
The feedback from these experts is used to improve either the teacher model by improving the quality of the initial pre-training data, the student model by enhancing and enriching the responses and output dataset used to fine-tune the student model, and by further refining the fine-tuned student model for retraining.
Midjourney has effectively used RLHF, for example, to continuously collect user feedback through their Discord-based UI. Users can select options to redo runs, create variants, and upscale the images they like the best.
The FMOps Toolkit
To tie all the techniques together:
- Model Distillation – Is the process of creating a smaller, task-specific model from a powerful, larger foundation model, usually by generating responses (aka labels, outputs, or predictions) that are then used for model training or fine-tuning;
- Fine-Tuning – Is a process for adapting an existing model to a domain specific dataset to improve performance on a specific set of tasks through supervised learning, with the resulting model used in an intelligent application;
- RAG – Is a pattern for injecting external information into a model, as either part of the context fed to the model through the user prompt or injected dynamically into the response, usually based on some kind of similarity match between the information and the prompt;
- Prompt Engineering – Is the practice of strategically designing and structuring input prompts to effectively guide an AI model's response, optimizing the model's performance in generating accurate, relevant, and contextually appropriate outputs;
- RLHF – Is a method of training AI models by using human feedback to reinforce desired behaviors, enabling the model to learn from human preferences and judgments, thereby refining its responses and actions in a more contextually and socially aware manner.
Practical Applications
The power of model distillation is it’s applicability across a wide range of practical use cases, including:
- Industry-Specific Solutions: In healthcare for rapid diagnosis, and in finance for real-time fraud detection. Industries as varied as retail and ecommerce, media and entertainment, and even industrial can benefit from efficient ML workloads.
- Common Use Cases: Utilized in computer vision, natural language processing, speech recognition, recommendation systems, and neural architecture search.
Reasons why model distillation will become even more important in the future include:
- Compliance and Privacy: In certain cases, regulations or privacy concerns might restrict the use of cloud-based, large-scale AI models. Distilled models can often be deployed locally, offering a solution that respects privacy and regulatory constraints.
- Energy Efficiency and Sustainability: The environmental impact of running large-scale AI models is a growing concern. Distilled models require less computational power, which translates to lower energy consumption, aligning with the increasing need for sustainable AI practices.
- Improved Accessibility and User Experience: For applications like mobile apps or web services, using a distilled model means faster response times and lower bandwidth requirements, leading to a better user experience. This is particularly relevant for generative AI applications that interact directly with end-users, like chatbots or image generators.
Getting Started With Model Distillation Using Labelbox
Basic tools and platforms
Here’s what you’ll need to get started with model distillation:
- Access to a foundation model: A relevant foundation model that can be used as the parent model to generate responses from prompts or unstructured data like images or texts. For inspiration, here are all the models currently available on the Labelbox platform. Models not listed can still be incorporated from sites like HuggingFace.
- A training framework: Libraries like TensorFlow and PyTorch offer functionalities for model distillation, such as training and model pickling.
- A development environment or notebook: Model distillation can be done locally or in a cloud based IDE or notebook-based environment like Colab or Databricks notebook (even an MLOps platform like GCP’s Vertex AI).
- A platform for automating data and response preparation: A platform like Labelbox with capability to automate the data preparation process, generating either labels or predictions.
- A data storage and curation platform: Once the responses have been generated, a centralized repository for the inputs (or prompts) and the outputs (or responses) will be valuable, especially for future analysis. Labelbox provides a data curation and storage solution in the form of Catalog, which offers rich features for filtering multiple modalities (image, text, video, audio, and geospatial data).
Initial Steps
- If you’re just getting started, consider applying model distillation to train a student model in an offline, response-based manner using one of the popular foundation models for either a computer vision or natural language processing use case.
- Otherwise, be sure to decide on the following:
- Picking the teacher and student models: What model will be used for the teacher model? What model will be used for the student model (if fine-tuning) or will model training happen from scratch?
- Picking the knowledge type: What kind of knowledge do you want to capture? Do you want to mimic the responses? The internal features? The relationship between the inputs and outputs?
- Picking the training method: How will you train the student model? Offline? Continuously or online? Self-train via self-distillation?
Next Steps: Applying Model Distillation In Practice
In the upcoming parts of the series, you’ll get a chance to see how simple and easy it is to get started with model distillation using Labelbox’s Catalog and our data engine.
In Part 2 of the series, we’ll demonstrate an end-to-end workflow for computer vision, using model distillation to fine-tune a model with labels created in Labelbox's data engine using Amazon Rekognition.
In Part 3 of the series, we’ll demonstrate an end-to-end workflow for NLP, using model distillation to fine-tune a BERT model with labels created in Labelbox using PaLM2.
Conclusion
In this introduction we’ve barely scratched the surface of model distillation. The standard approach to distillation encourages the distilled model to emulate the hidden states of the larger teacher model.
How can we augment the standard approach with methods that align structured domain knowledge (like we’d see in knowledge graphs, entity-relational graphs, markup-languages, causal models, simulators, process models, etc.). Only time will tell.
Still, model distillation presents an exciting frontier in the AI world, offering a blend of efficiency and performance. As AI developers, integrating distillation into your workflows can lead to more efficient, cost-effective, and innovative AI solutions. The future of AI is not just in building larger and larger models. The future will be about developing more intelligent applications requiring smaller and smarter task-specific models.
Model distillation is a key step in that direction.
We’re happy to help answer any questions. Reach out to us anytime on our contact us page.


