
 All guides
All guidesDistilling a faster and smaller custom LLM using Google Gemini

The race to both mimic and create competitor models to OpenAI’s GPT3.5 energized the interest in model compression and quantization techniques.
Knowledge distillation, also known as model distillation, is one of many techniques that have grown in popularity and importance in enabling small teams to leverage foundation models in developing small (but mighty) custom models, used in intelligent applications.
In “A pragmatic introduction to model distillation for AI developers”, we illustrated some of the conceptual foundations for how model distillation works as well as why we even need smaller models.
We also provided an in-depth guide with a worked example in the second part of our series, “End-to-end workflow with model distillation for computer vision”.
Now we turn our attention to demonstrating the flexibility and power of model distillation in another domain and use case, where increased efficiency through supervised training of a smaller model by a foundation model is necessary.
In this tutorial we’ll demonstrate an end-to-end workflow for natural language processing, using model distillation to fine-tune a BERT model with labels created in Model Foundry using Google Gemini.
We’ll show how easy it is to go from raw data to cutting-edge models, customized to your use case, using a sentiment dataset (additional public datasets can be found here or on sites like Kaggle or HuggingFace).
In less than 30 min you’ll learn how to:
- Ingest, explore and prepare the sentiment dataset;
- Pick and configure any text-based foundation model to automatically label data with just a few clicks;
- Export the labeled predictions to a project as a potential set-up for manual evaluation;
- Use the labeled predictions dataset to fine-tune a student model using a cloud-based notebook provider;
- Evaluate performance of the fine-tuned student model.
At the end of the tutorial we’ll also discuss advanced considerations in scaling your models up and out, such as automating data ingestion and labeling, and resources for incorporating RLHF into your workflows.
See it in action: How to use model distillation to fine-tune a small, task-specific Language Model
The walkthrough below covers Labelbox’s platform across Catalog, Annotate, and Model. We recommend that you create a free Labelbox account to best follow along with this tutorial. You’ll also need to create API keys for accessing the SDK.
Notebook: Text Bert Model Distillation
Overview
The Model Distillation Workflow for NLP
In our prior post on model distillation concepts, we discussed the different model distillation patterns, based on the following criteria:
- The type of Teacher model architecture used;
- The type of Student model architecture used;
- The type of knowledge being transferred from teacher to student model(s) (response-based, feature-based, relation-based knowledge);
- The cadence and scheme for how the student mode is trained (offline, online, self).
“Benefits of Using Model Distillation”, Source: “A pragmatic introduction to model distillation for AI developers”, Fig 3.1
In this tutorial we’ll be demonstrating the most popular and easiest pattern to get started with: offline, response-based model (or knowledge) distillation.
The teacher model we’ll be using to produce the responses is Google Gemini and the student model is BERT (distilbert-base-uncased).
As you’ll see, we could have chosen any combination of teacher or student models, because the offline, response-based pattern of model distillation is incredibly flexible.
When implementing this process for your own use case, it’s important to understand the relative strengths and weaknesses of each model and match them according to your requirements and use cases (whether it’s detecting and removing PII to be GDPR compliant or detecting unsavory content).
Using The Labelbox Platform To Automate Model Distillation
Labelbox is the data factory for genAI, providing an end-to-end solution for curating, transforming, annotating, evaluating and orchestrating unstructured data for data science and machine learning.
The Labelbox platform supports the development of intelligent applications using the model distillation and fine-tuning workflow enabling AI developers to easily:
- Import, curate, filter and eventually select the text that will be labeled for use in student model training and fine-tuning with Catalog. Additionally you can contextualize your data with custom metadata and attachments to each asset for greater context.
- Automate the labeling and annotation of the original text dataset using foundation models (or any pre-trained model, including custom models) in Model Foundry. The ability to leverage a variety of open source or third-party models to accelerate pre-labeling can cut labeling costs by up to 90% for teams with existing labeling initiatives (and kickstart new and budget constrained AI developers operating without manual labeling capabilities).
- Leverage human-in-the-loop evaluation (and RLHF) through the Foundry to Annotate integration, so labels can be reviewed before being used for training or fine-tuning.
- Integrate with some of the most common cloud providers like Google Cloud Platform and Databricks for additional MLOps services.
- Orchestrate and schedule future automated labeling and model runs as new data flows into the Labelbox platform through Model Apps (including multimodal data labeling).
Introduction To Data Preparation for Natural Language Processing With Catalog
Before beginning the tutorial:
- Create a free HuggingFace account (in order to access the "Setfit/emotion" dataset)
- Download the dataset locally
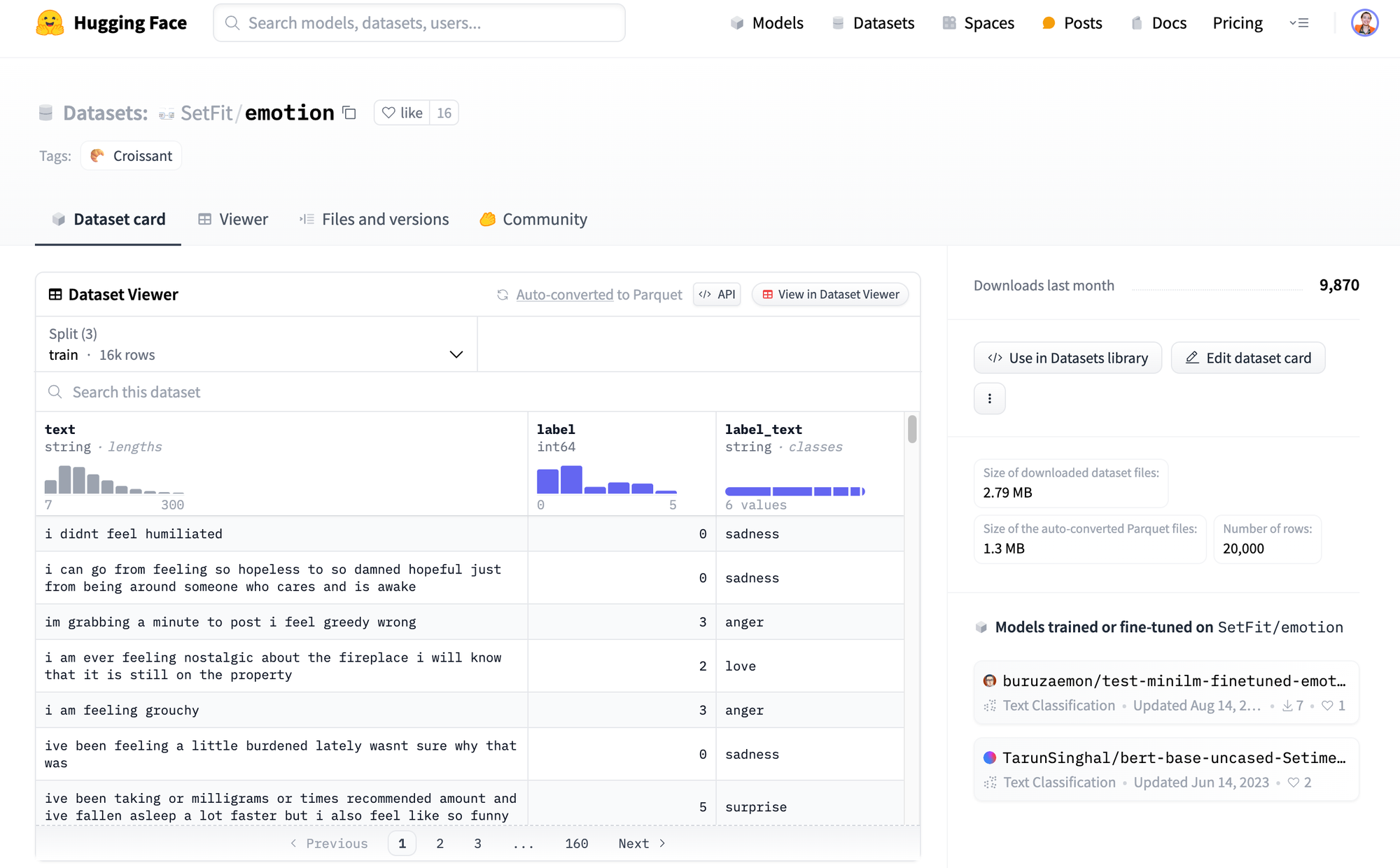
- Create a free Labelbox account (in order to create a free API key)
- Navigate to “Catalog” in the sidebar
- Select “+New”
- Upload the dataset from Kaggle
- Note: The easiest method is to use the Labelbox Web UI to manually upload your dataset.
- If your goal is to scale the data ingestion process for future labeling or data refreshes, check out our SDK.
Once you’re able to see your dataset in Labelbox Catalog, you’ll be able to do the following:
- Search across datasets to narrow in on data containing specific attributes (e.g metadata, media attributes, datasets, project, etc.)
- Automatically find similar data in seconds with off-the-shelf embeddings
- Filter data based on natural language and flexibly layer structured and unstructured filters for more granular data curation.
For additional details on how to use Catalog to enable data selection for downstream data-centric workflows (such as data labeling, model training, model evaluation, error analysis, and active learning), check out our documentation.
Using A Large NLP Model Or LLM To Generate And Distill Predictions For Fine-Tuning
The first step of model distillation is to identify an appropriate teacher model, which will be used to produce responses that, when combined with the original text, will serve as the fine-tuning dataset for the student model.
Response-based model distillation is powerful because it can be used even when access to the original model weights is limited (or the model is so big that downloading a copy of the model would take a really long time). Response-based distillation also doesn’t require the user to have trained the model themselves; just that the model was pre-trained.
Labelbox allows you to pick any of the currently hosted, state-of-the-art models to use (as well as upload your own custom models) to use as the teacher model.
For now, let’s get started with preparing the text we’ll be labeling, or generating predictions with, using Google Gemini. The combination of text and label pairs will be used for BERT.
Step 1: Select text assets and choose a foundation model of interest
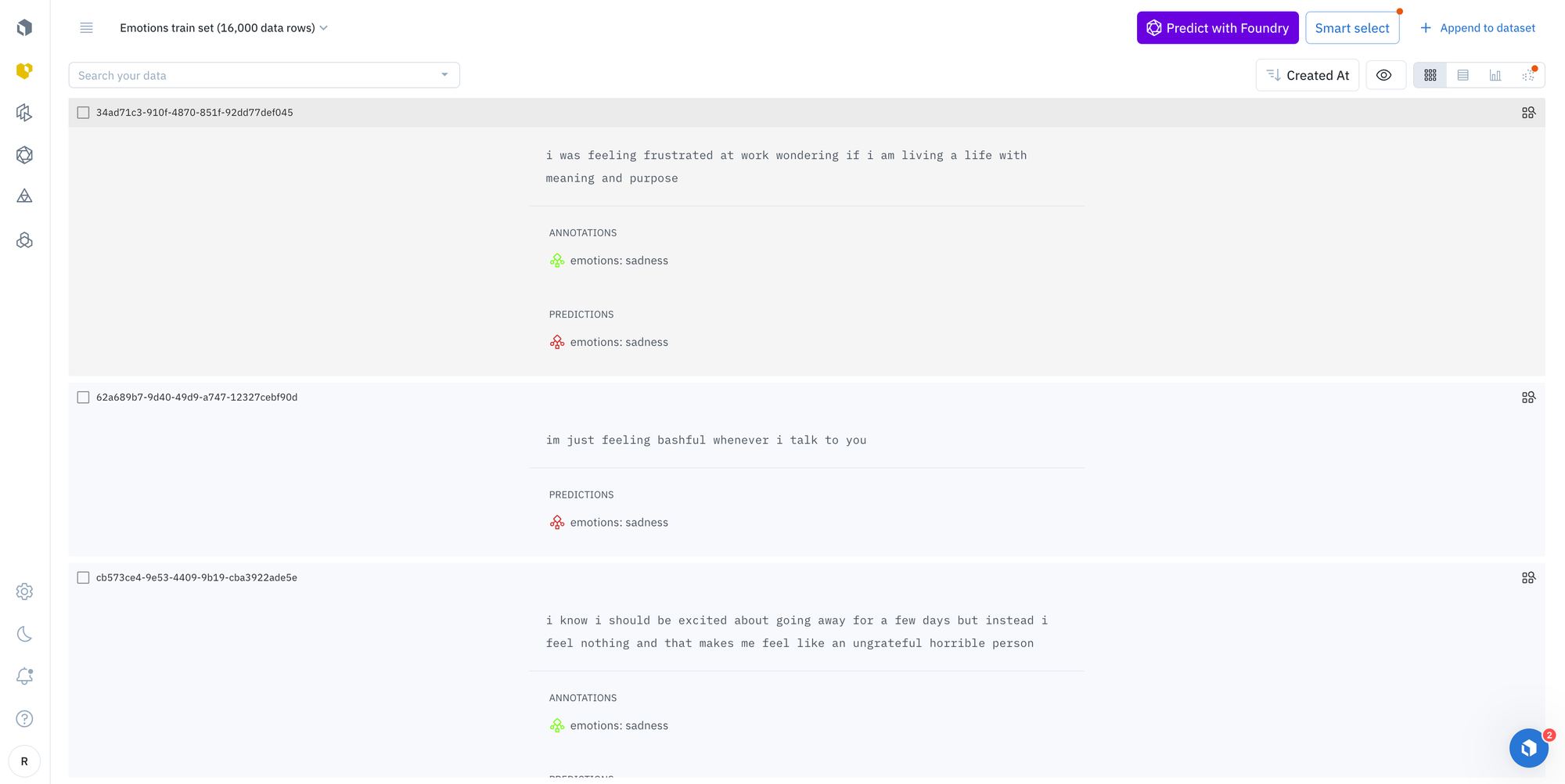
Steps:
- Navigate to your uploaded Emotions dataset in Catalog.
- To narrow in on a subset of data, leverage Catalog’s filters including media attribute, a natural language search, and more, to refine the text on which the predictions should be made.e.
- Once you’ve surfaced data of interest, click “Predict with Model Foundry”.
- You will then be prompted to choose a model that you wish to use in the model run (in this case Gemini).
- Select a model from the ‘model gallery’ based on the type of task - such as text classification, summarization, and text generation.
- To locate a specific model, you can browse the models displayed in the list, search for a specific model by name, or select individual scenario tags to show the appropriate models available for the machine learning task.
Step 2: Configure model settings and submit a model run
When developing ML based applications, developers need to quickly and iteratively prepare and version training data, launch model experiments, and use the performance metrics to further refine the input data sources.
The performance of a model can vary wildly depending on the data used, the quality of the annotations, and even the model architecture itself. A necessary requirement for replicability is being able to see the exact version of all the artifacts used or generated as a result of an experiment.
Labelbox will snapshot the experiment, the data artifacts as well as the trained model, as a saved process known as a model run.
This includes the types of items the model is supposed to identify and label, known as an ontology.
Each model has an ontology defined to describe what it should predict from the data. Based on the model, there are specific options depending on the selected model and your scenario.
For example, you can edit a model ontology to ignore specific features or map the model ontology to features in your own (pre-existing) ontology.
Each model will also have its own set of settings, which you can find in the Advanced model setting.
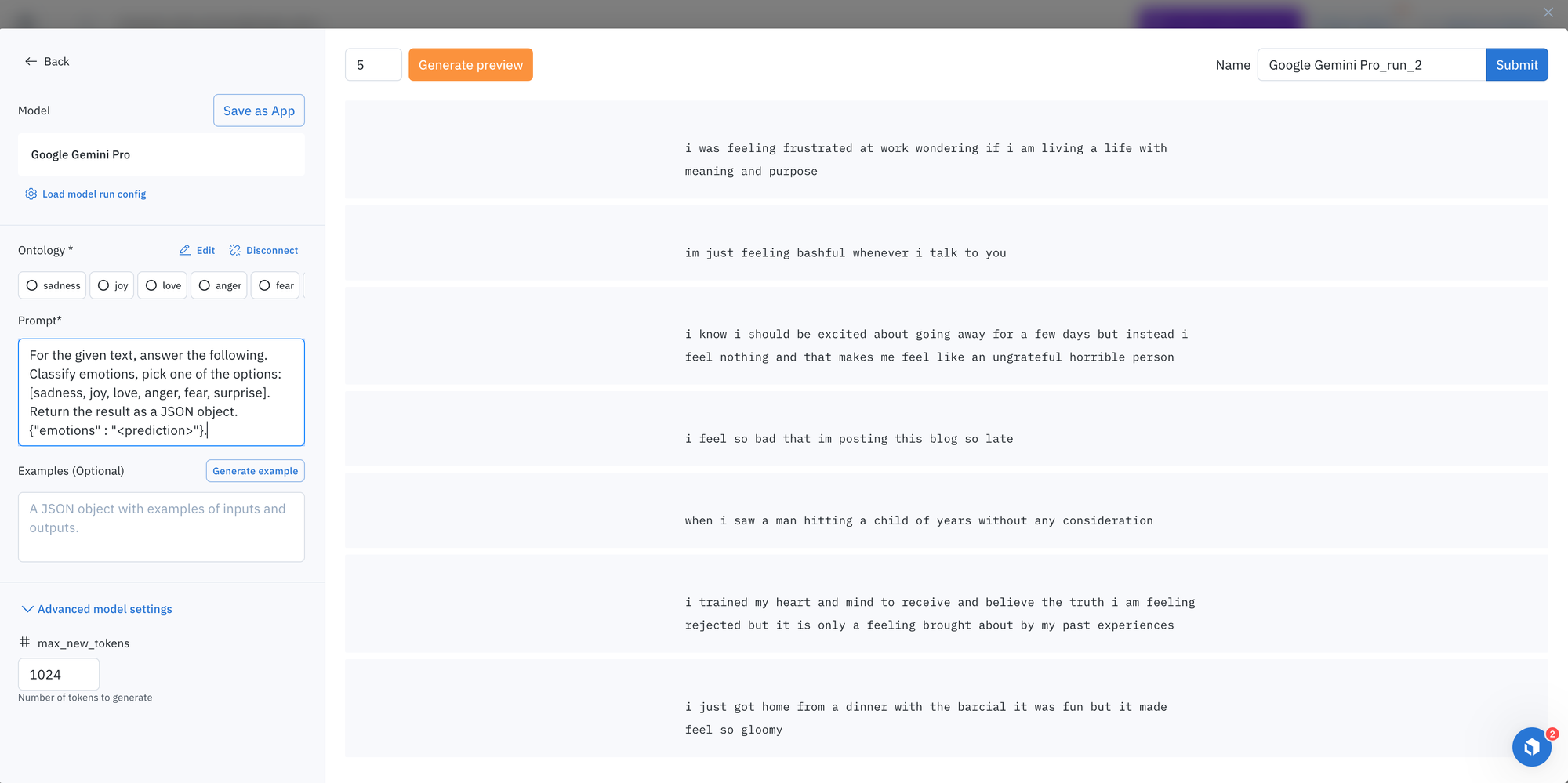
Steps:
- Once you’ve located Gemini, you can click on the model to view and set the model and ontology settings or prompt.
- In this case, we will enter the following prompt:
- For the given text, answer the following. Classify emotions, pick one of the options: [sadness, joy, love, anger, fear, surprise]. Return the result as a JSON object. {"emotions" : ""}.
This prompt is designed to facilitate responses from the model with one of the following: sadness, joy, love, anger, fear, surprise.
While this step is optional, generating preview predictions allows you to confidently confirm your configuration settings:
- If you’re unhappy with the generated preview predictions, you can make edits to the model settings and continue to generate preview predictions until you’re satisfied with the results.
- Once you’re satisfied with the predictions, you can submit your model run.
Step 3: Review predictions in the Model tab
Because each model run is submitted with a unique name, it’s easy to distinguish between each subsequent model run.
When the model run completes, you can:
- View prediction results
- Compare prediction results across a variety of model runs different models
Use the prediction results to pre-label your data for a project in Labelbox Annotate
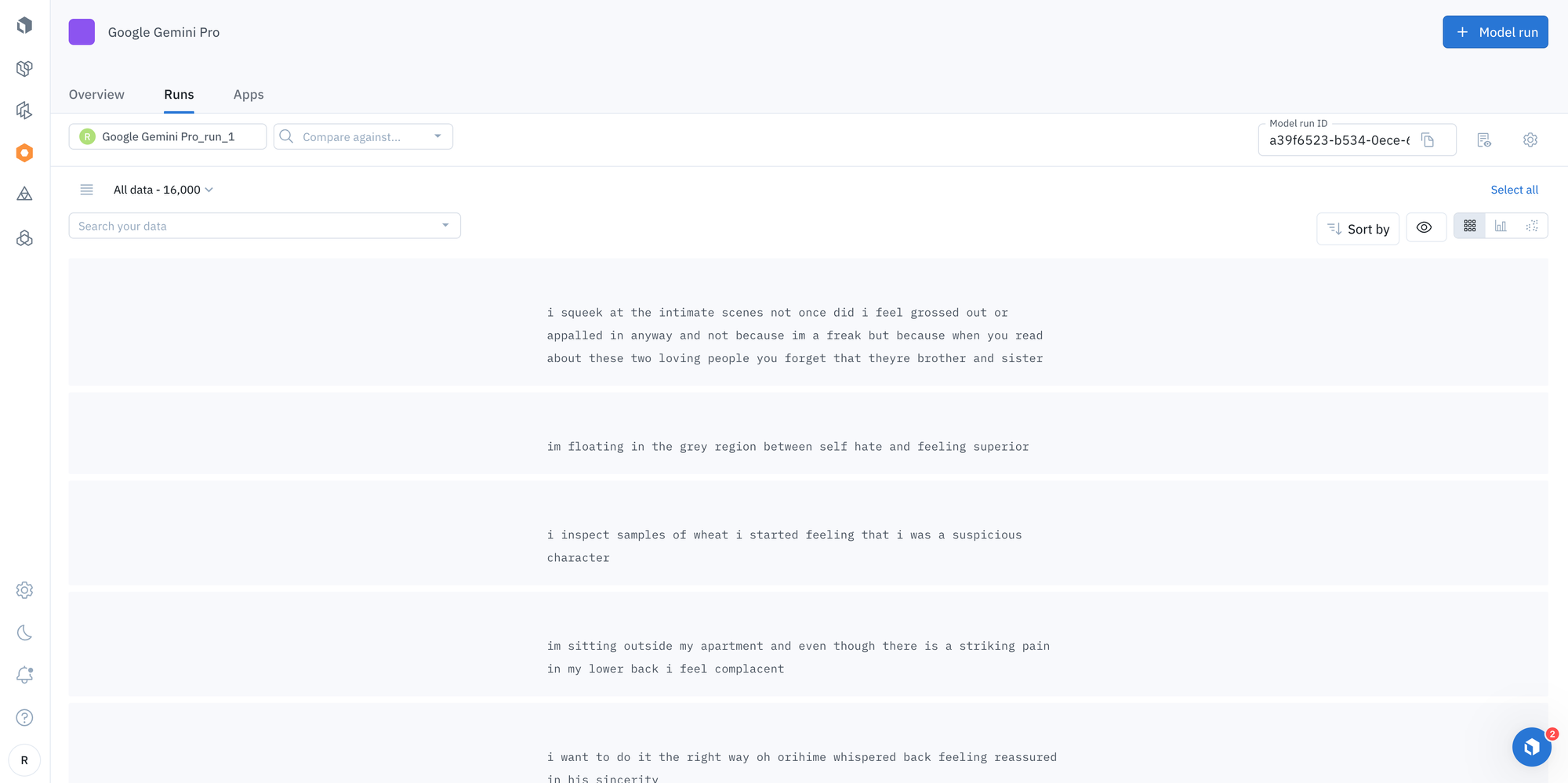
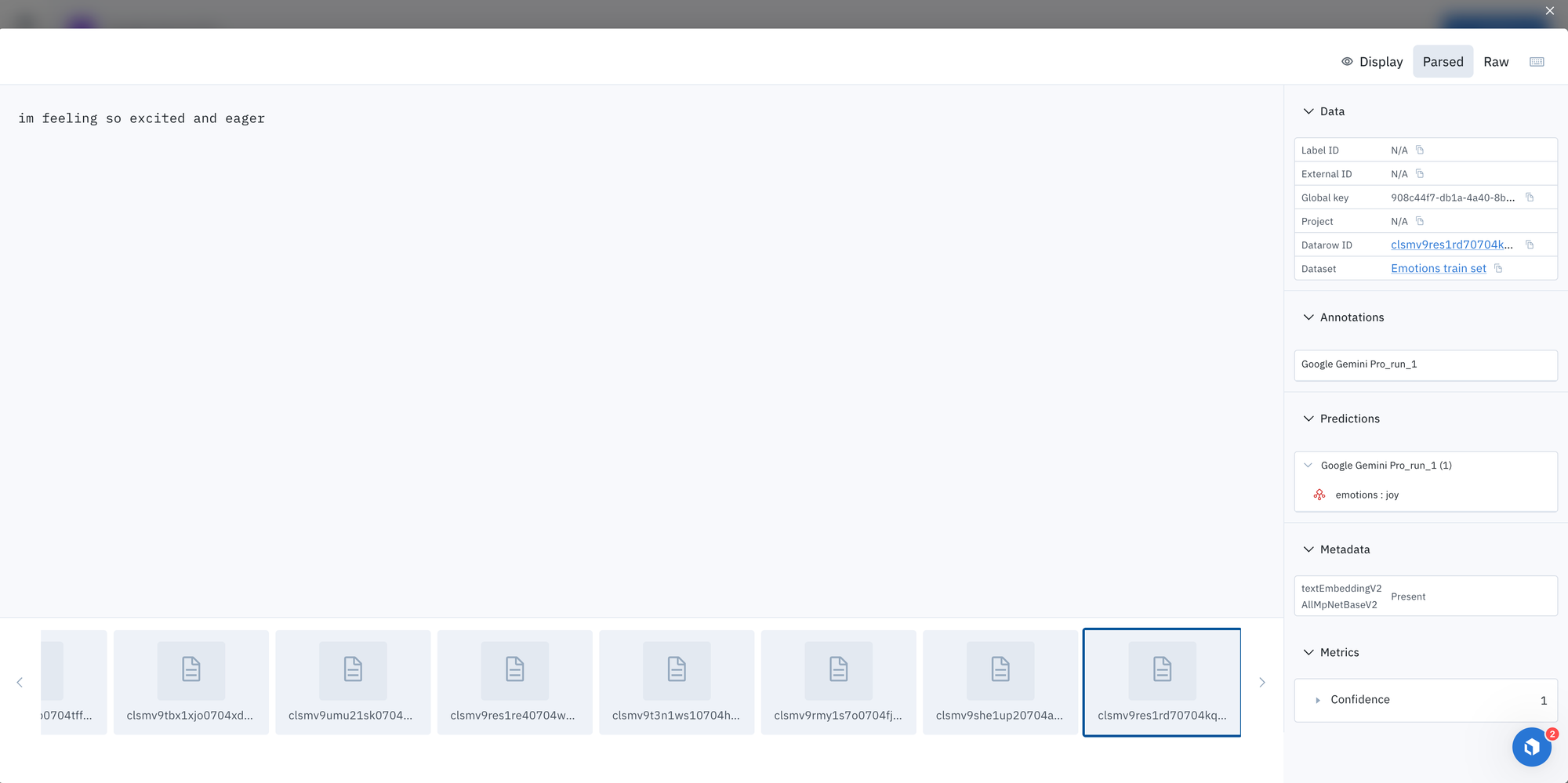
- These generated labels are now ready to be used for fine-tuning the BERT student model.
Step 4: Enriching and evaluating predictions using human-in-the-loop and Annotate
Although fine-tuning a foundation model requires less data than pre-training a large foundation model from scratch, the data (specifically the labels) need to be high-quality.
Even big, powerful foundation models make mistakes or miss edge cases.
You might also find that there are additional categories that the parent model didn’t identify correctly because the ontology was incomplete.
Once a parent model like Gemini has been used for the initial model-assisted labeling run, those predictions can then be sent to a project, a container where all your labeling processes happen.
- In this case, we feel fairly confident in how well Gemini performed so we’ll send the inferences to the corresponding Labelbox project and treat them as the ground truth that the student model will be fine-tuned on.
Fine-Tuning The Student Model (BERT)
We’ve shown the first half of the model distillation to fine-tuning workflow.
- We identified the categories we wanted the parent model (Gemini) to detect and label in the form of an ontology.
- We used Gemini to automatically label the texts as "sadness" or "fear" (for example).
- We exported the generated labels to a Labelbox project, at which point we could review the labels manually and enrich them further using the Labelbox editor.
The next step is to use the generated labels, along with the original texts, to fine-tune a student model in Colab.
Note: You’ll now need the API keys from earlier to follow along with the Colab notebook.
Step 5: Fetch the ground truth labels from the project via Labelbox SDK
For brevity, we’ve omitted the surrounding code samples but you can copy or run the corresponding blocks in the provided notebook.
Check out our documentation to find out all the ways you can automate the model lifecycle (including labeling) using our SDK.
Steps:
- Before fine-tuning the BERT student model, we’ll need to fetch the generated labels from the Labelbox project using the Labelbox SDK as well as the ground truth.
Step 6: Additionally Text Data Processing
There's additional processing that needs to happen, which we walk through below.
Steps:
- Next we’ll ensure the labels are exported into a .csv file that contains two columns, the original ‘text’ and the generated ‘label’.
- We’ll read the csv file into a pandas dataframe, perform a series of aggregation operations to help us splits the text into train and test sets based on the category count.
- We’ll initialize a tokenizer and encode the train and test texts.
- Finally we’ll finish creating the training & validation dataset.
- Note: Expand the “Export labels into .CSV file” block in the Colab notebook for the full code sample.
Step 7: Fine tune student BERT model using labels generated by Google Gemini
Steps:
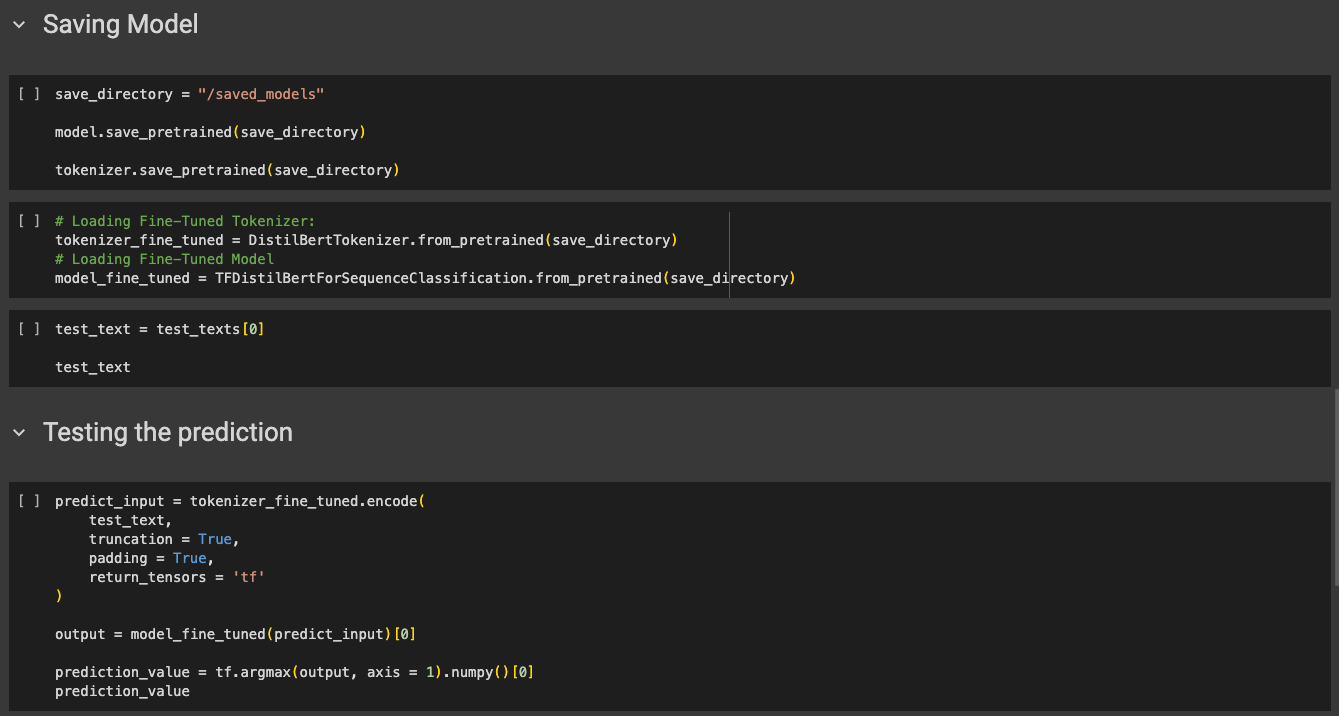
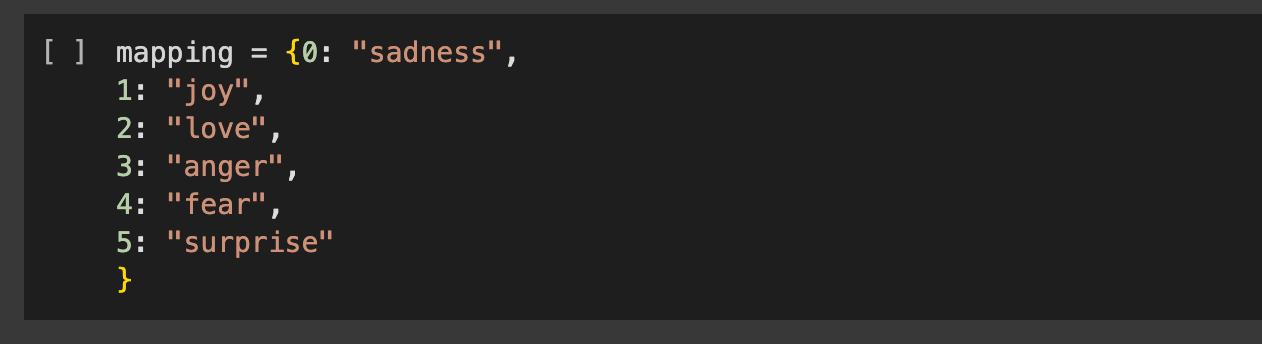
- In Colab we’ll instantiate a BERT model and train it using the data, which includes both text and labels. Specifically we'll fine-tune a text classifier model called “distilbert-base-uncased” to classify text as one of the following categories in the ontology: sadness, joy, love, anger, fear, surprise.
- We’ll also save the model and test the prediction.
- By saving the model (or every model we create) we have the option of A/B testing models and using the models for downstream use cases (as well as share the models with other key stakeholders through a model registry, like MLFlow).
Step 8: Create a model run with predictions and ground truth
Oftentimes the initial training or fine-tuning step isn’t the final stop on the journey of developing a model.
One of the biggest differences between the traditional method of training models in the classroom versus the real-world is how much control you have over the quality of your data, and consequently the quality of the model produced.
As we mentioned earlier, developers can upload predictions and use the Model product to diagnose performance issues with models and compare them across multiple experiments.
Doing so automatically populates model metrics that make it easy to evaluate the model’s performance.
Steps:
- First, you’ll grab the model’s ID to create a new model run (if needed).
- Then you’ll get the ground truth from your project via the export as well as the label IDs from ground truth.
- Next you’ll create the predictions by running the fine-tuned BERT model on the original text assets.
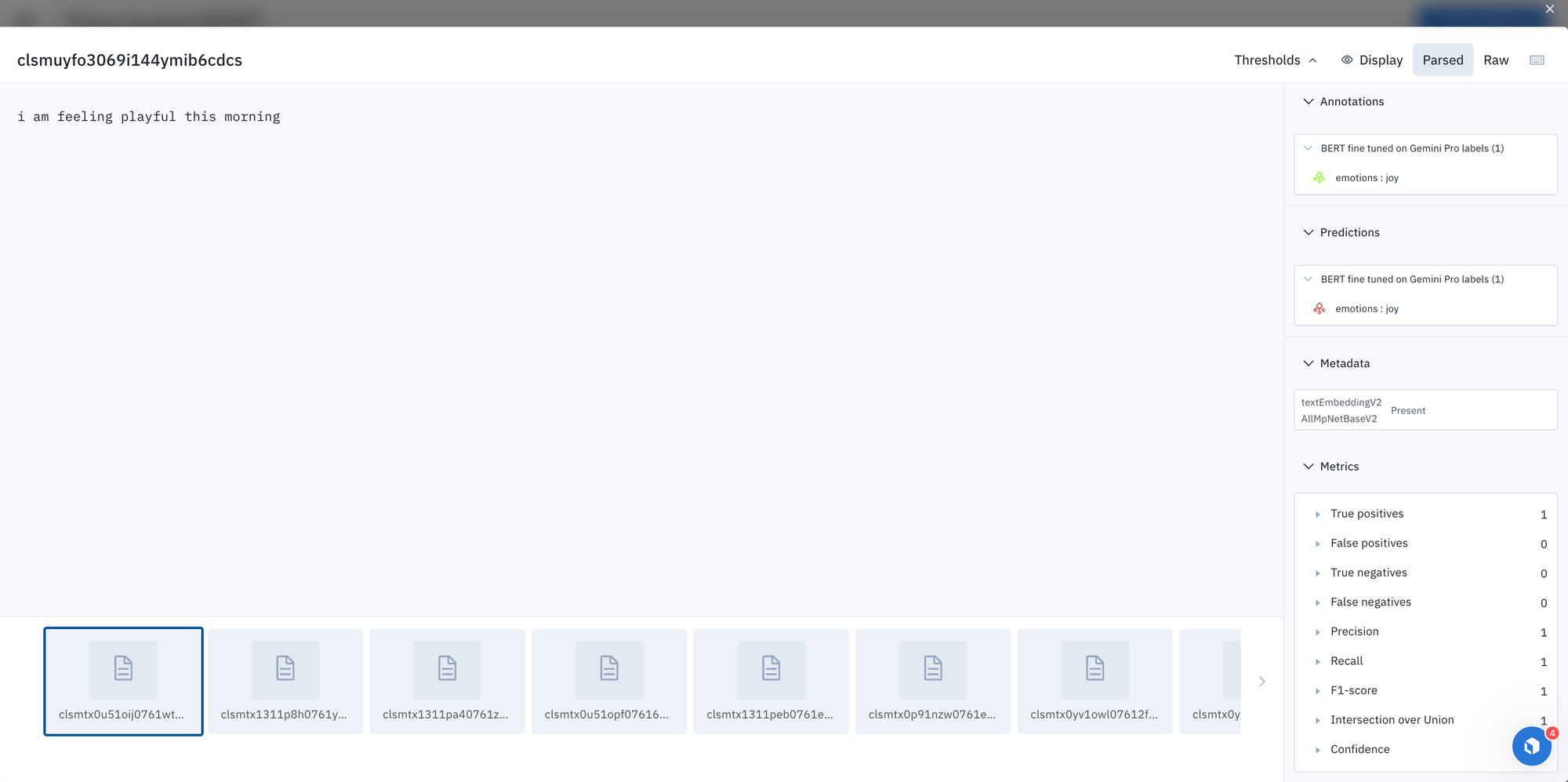
- You can then upload the ground truth labels (the labels generated by Gemini and used as the fine-tuning dataset) and the predictions from the fine-tuned BERT model to the corresponding Labelbox model.
- You can see an example of how model metrics are automatically populated by Labelbox.
Evaluating Model Performance
There’s no single metric to rule them all when evaluating how your fine-tuned LLM performs.
Both qualitative and quantitative measures must be considered, combined with sampling and manual review.
With that being said, Model offers a number of the most common out-of-the-box. With the ‘Metrics view’ users can drill into crucial model metrics, such as confusion matrix, precision, recall, F1 score, false positive, and more, to surface model errors.
Model metrics are auto-populated and interactive, which means you can click on any chart or metric to immediately open up the gallery view of the model run and see corresponding examples, as well as visually compare model predictions between multiple model runs.
Step 9: Evaluate predictions from different BERT model runs in Labelbox Model
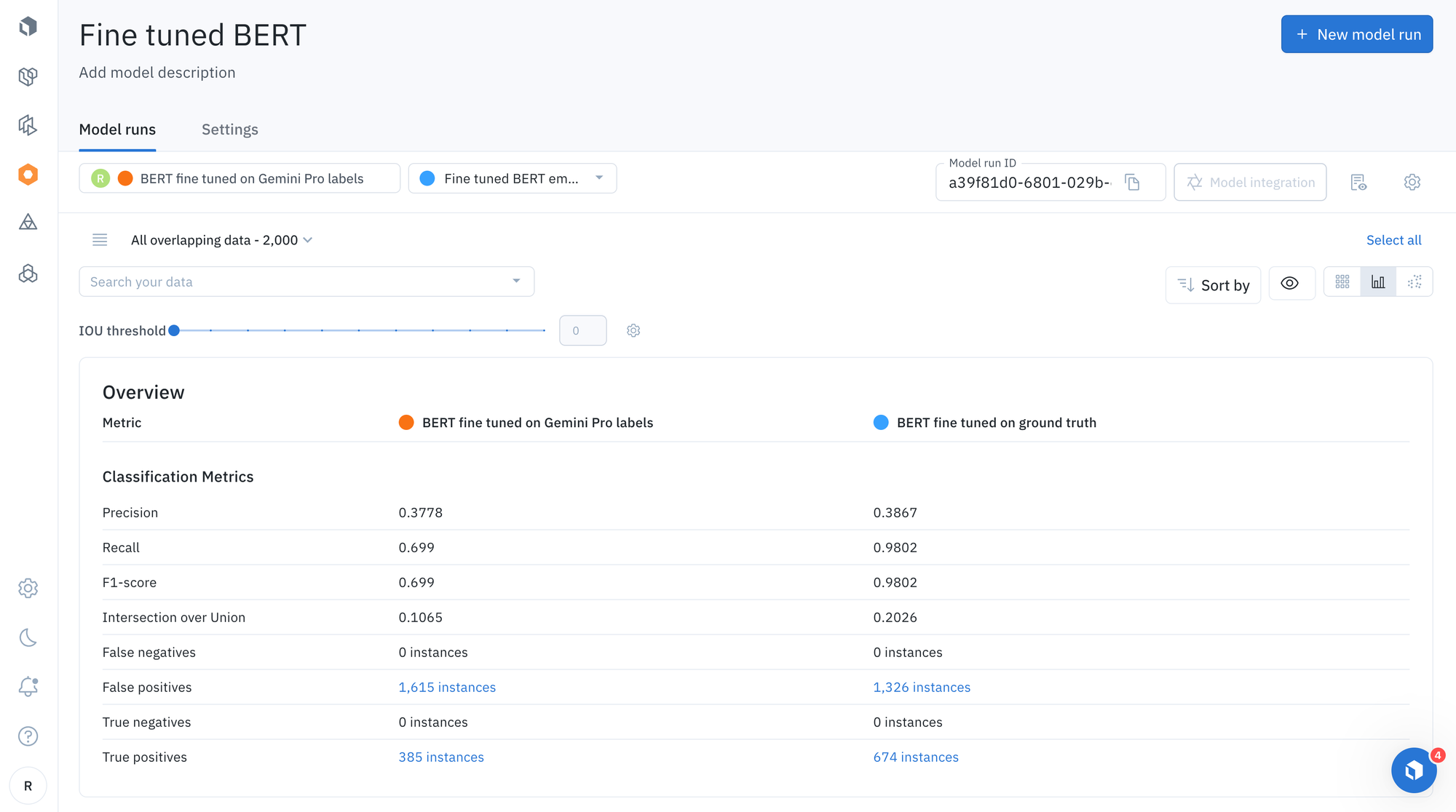
Steps:
- Navigate to “Model”
- In this case, we fine-tuned two models, one using 1000 ground truth labels and the other with 1000 labels generated by the Gemini model. We see very similar results and leveraging an off the shelf model is almost as good as using ground truth labels.
Examples of predictions from fine tuned BERT model
How does our fine-tuned model perform?
Let's manually inspect a few examples of predictions from the fine-tuned BERT model.
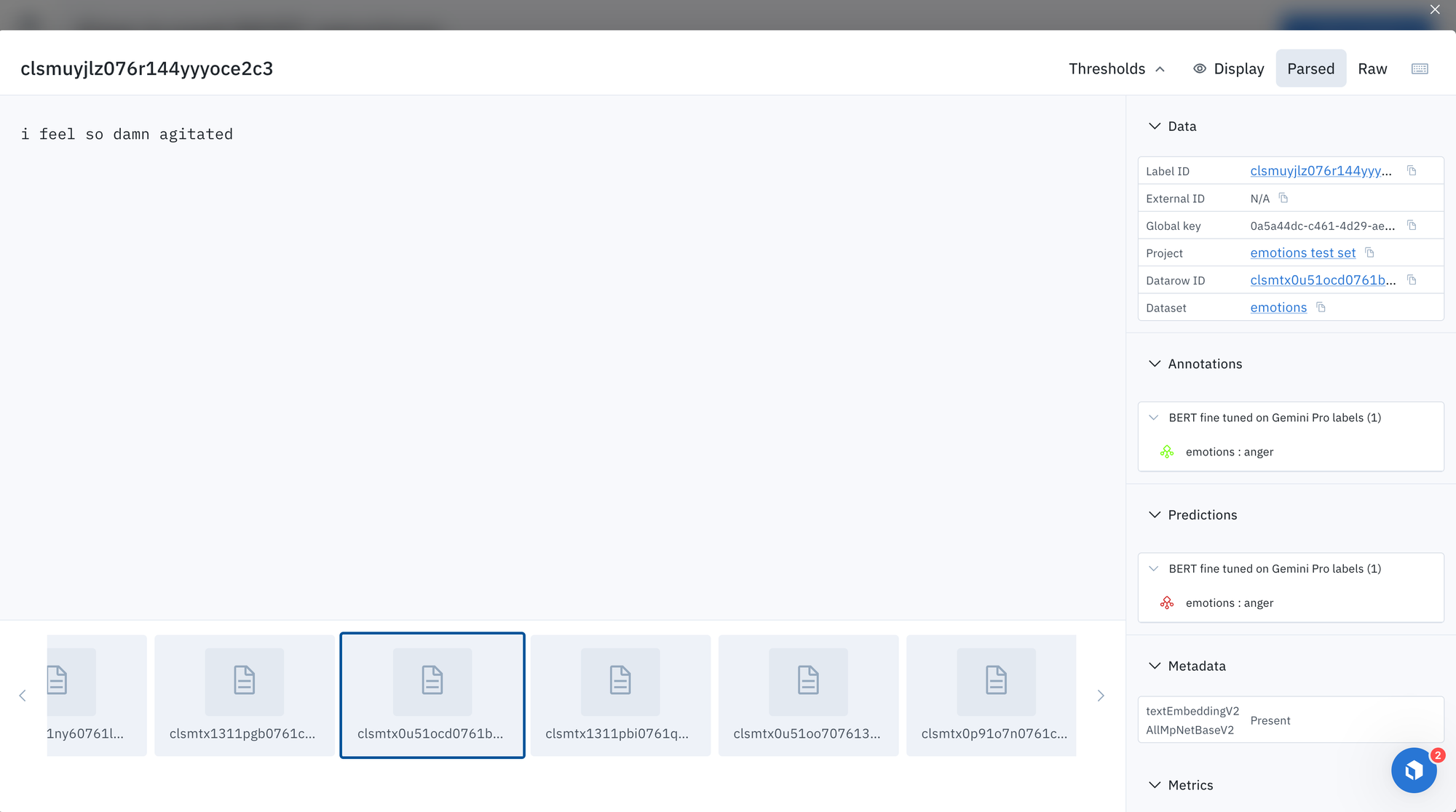
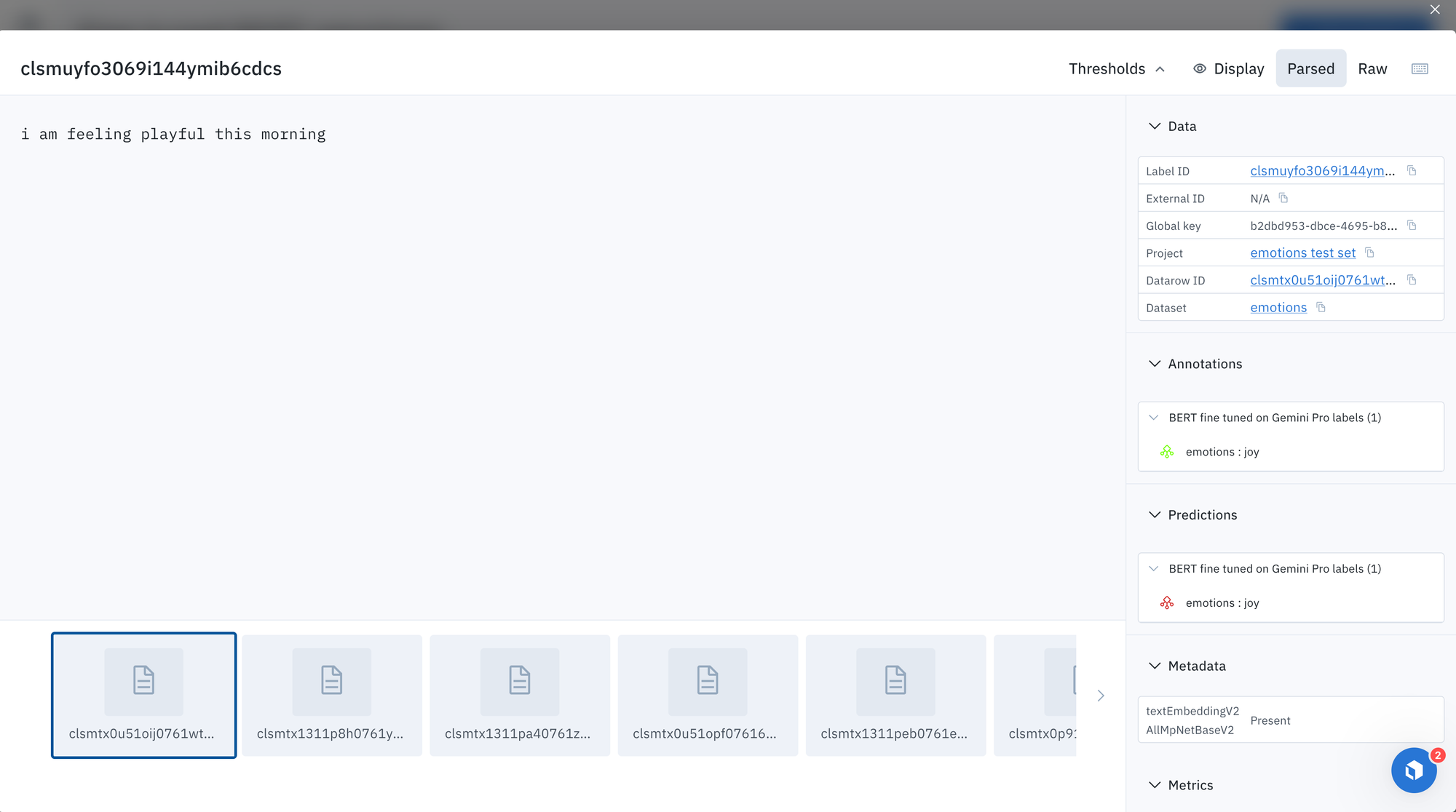
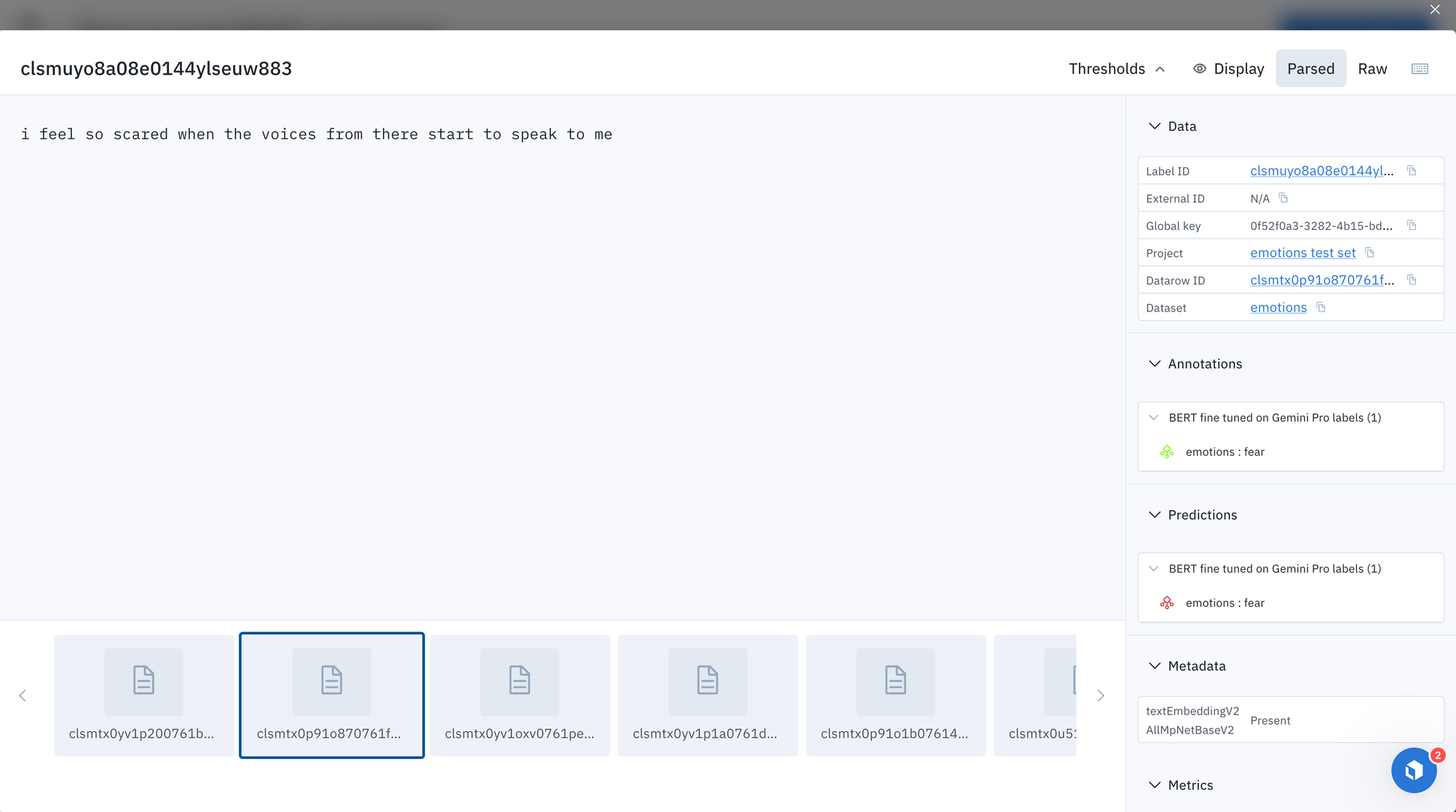
Advanced Considerations
In this step-by-step walkthrough, we’ve shown how anyone with any text-based dataset can leverage an LLM to label, fine-tune and analyze a smaller but mighty custom model.
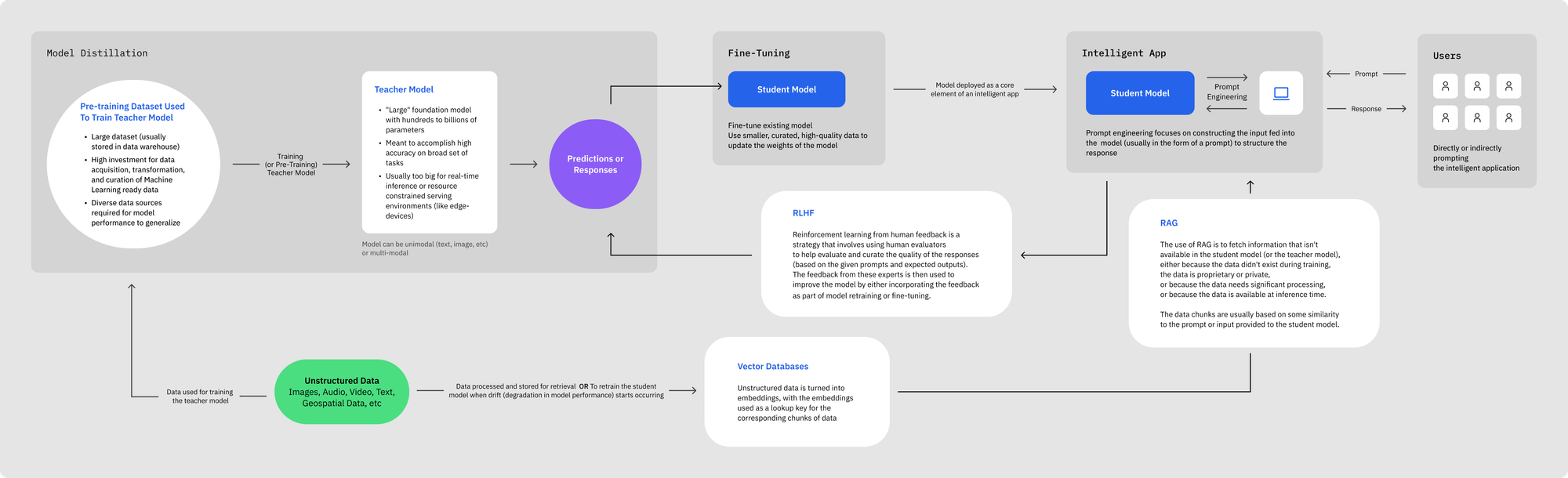
Additional considerations users should address for scaling similar projects include:
- Collecting feedback from users & human SME’s to improve the fine-tuning dataset quality on a continuous basis, including error analysis and human preference modeling;
- Strategic planning for incorporating multiple data modalities besides text, including image, audio, and video;
- Automating future data ingestion, curation, enrichment, and labeling when the fine-tuned model needs to be retrained due to drift via a robust SDK;
- Easy-to-use, user interface that can be customized for various modalities of data when multiple users are involved (as well as LLM data generation).
Conclusion
In this tutorial we demonstrated an end-to-end workflow for natural language processing, using model distillation to fine-tune a BERT model with labels created in Model Foundry using Google Gemini.
Hopefully you were able to see how easy it is to go from raw data to cutting-edge custom models in less than 30 min.
You learned how the Labelbox platform enables model distillation by allowing developers to:
- Ingest, explore and prepare text-based datasets using Catalog;
- Use any LLM to automatically label data using Model Foundry as well as how to incorporate human-in-the-loop evaluation using Annotate;
- Export these labeled predictions to a cloud-based training environment for fine-tuning;
- Automate the various workflows using the Labelbox SDK;
- Evaluate model performance and analyze model errors using Labelbox Model.
If you’re interested in learning more about model distillation, check out the previous posts in this series: “A pragmatic introduction to model distillation for AI developers”, “End-to-end workflow with model distillation for computer vision”.
Looking to implement a production-ready model distillation and fine-tuning in your organization but not sure how to get started leveraging your unstructured data?
Ask our community or reach out to our solutions engineers!


